This article will compare several popular time series databases and evaluate their suitability for third-party applications.
Introduction
Time-series data has become necessary in modern applications, from IoT sensor data to predictive maintenance and environmental monitoring. Time-series databases are purpose-built to handle this type of data, providing optimized storage and retrieval for large volumes of time-series data.
For third-party applications that rely on time-series data, choosing the right database can ensure performance, scalability, and reliability. Check out What to look for in historian for third-party integration for what characteristics to watch out for when selecting a historian.
Enterprise data historian functionality at a fraction of the cost. Industrial time series data collection & analytics tools.
dataPARC Historian
The dataPARC Historian is a great choice for third-party applications. It checks all the boxes and is found to be a well-rounded and easy-to-use historian. The dataPARC Historian architecture is optimized for integration because data is only valuable when it is utilized, take advantage of open standard protocols to ensure third-party applications can easily and economically integrate with the data.
The dataPARC Historian offers everything one can expect from a mission-critical plant data historian product, including essential accessibility, performance, and security.
Easy to Integrate
dataPARC provides a variety of integrations with third-party tools and applications, making it easy to connect to other systems and services. It also provides APIs and SDKs for developers to build custom integrations.
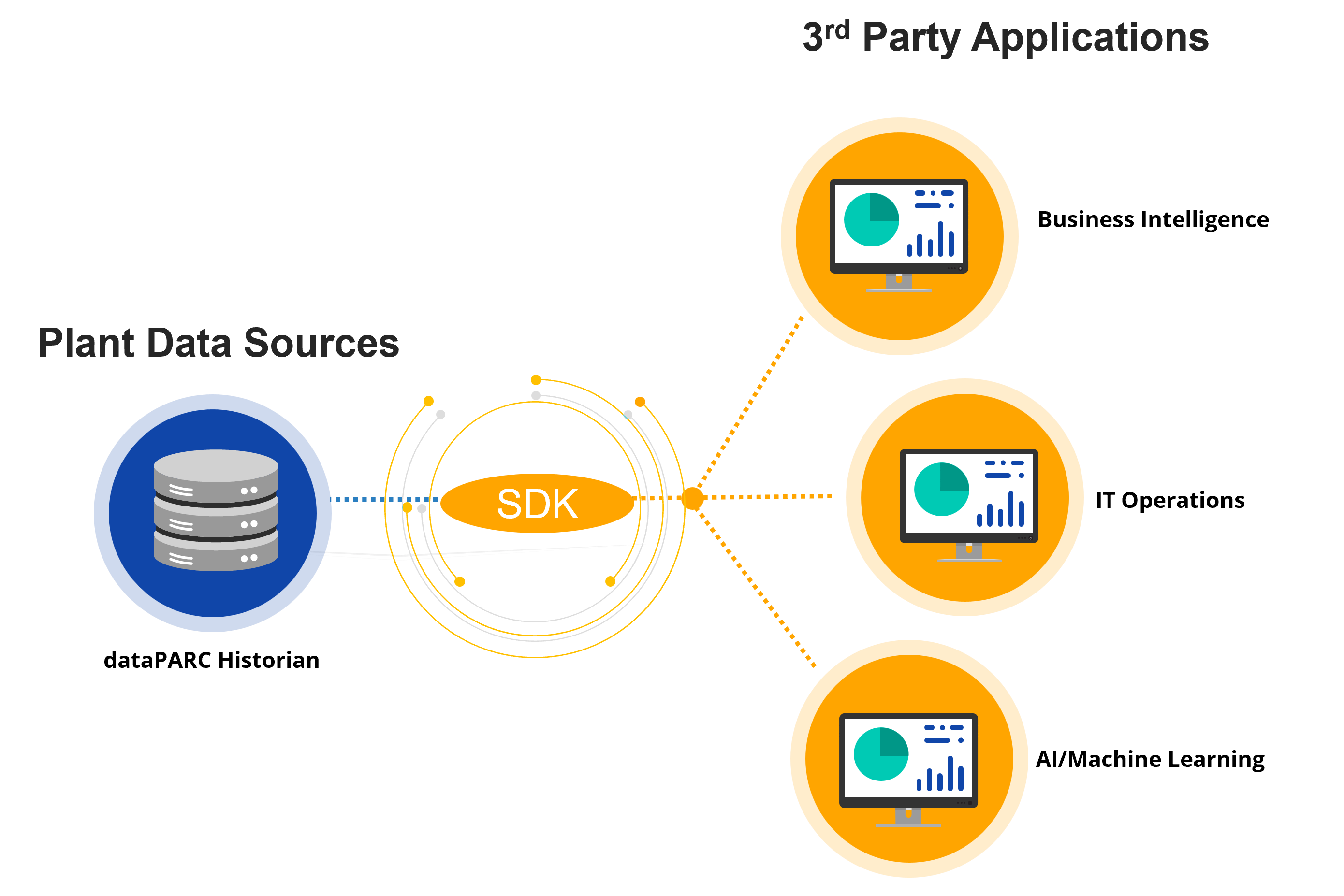
A flexible data pathing SDK allows external applications to query data for a variety of use cases.
The SDK is designed for external applications to access Historian data easily and efficiently. The SDK is optimized for common use cases, such as trend and real-time model execution.
Easy to Configure
A management portal allows for centralized configuration. All sources can be managed in one place, and it is accessible online. There is no need to remote into a specific server to check or make modifications to your sources. Connect new sources, add tags, and check statutes from one application.
The Historian supports various data types, including numeric, string, and binary data, and allows users to define custom tags and fields for their data.
Scalability and Performance
The dataPARC Historian is not limited by tag count, big or small. Suitable for systems with hundreds or millions of tags. The dataPARC Historian’s architecture can accommodate small operations as well as multi-location enterprises. Additional data sources and storage capacity can be incorporated seamlessly.
Reduce latency and optimize Historian architecture to make it even faster to see the latest data from sensors in the field. The dataPARC Historian is 10x faster for common scenarios.
Data collectors utilize “store and forward” technology to buffer and store data, ensuring maximum integrity by preventing data loss during a network failure. Options for Historian redundancy and fail-over tolerance provide consistent access to data.
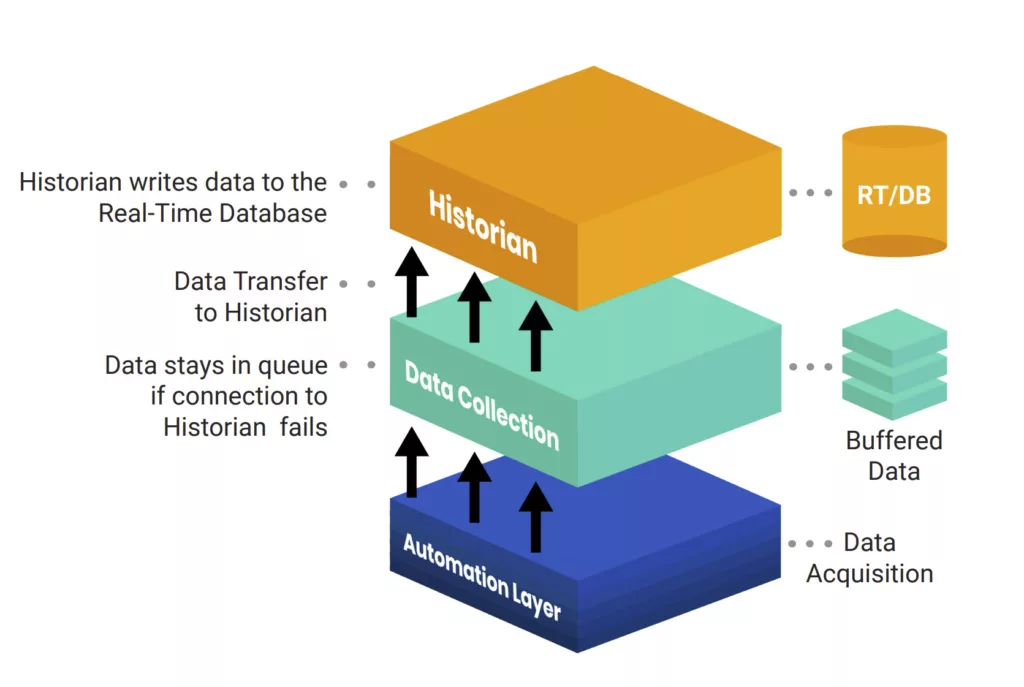
The collector buffers data locally and validates successful transmission to the Historian before clearing the queue.
The collector buffers data locally and validates successful transmission to the Historian before clearing the queue. This technology prevents data loss when connection to the Historian server is lost–like during network hardware failures or the Historian server itself. In complex network architectures, like multiple domains, this technology becomes more and more critical.
Company Size
dataPARC is a Goldilocks size for third-party application partnerships. dataPARC itself has about 100 employees, which may seem small, but they have the backing of their parent companies, BTG and Voith. Giving them access to key resources. dataPARC is small enough to listen to customers’ and partners’ feedback and large enough to take that feedback and adjust products as needed to ensure their customers succeed.
Continuous Improvement and Adaptability
In 2022, dataPARC revamped the dataPARC Historian, making it faster and easier to configure and access data. This shows the growth and effort that dataPARC is putting into the Historian now and for years to come.
dataPARC has two main products, the dataPARC Historian and PARCview the data visualization software. With two main products, dataPARC can spend adequate time resolving any issue that may arise and work on new features to continuously improve the product.
Cost
The dataPARC historian is licensed on a per-tag basis. This makes it cost-effective for any size implementation. Easy access and inclusion of all plant data at a low cost.
dataPARC is a versatile and comprehensive time-series database that offers advanced query capabilities, scalability, and high performance, making it a great option for third-party applications that need to manage vast quantities of time-series data.
Canary Historian
Canary Lab is an adaptable time-series database. Data is organized into data sets, grouping together sensors or tags how you choose. They mention their Historian is for extra small and enterprise customers alike.

Ease to Configure
We were unable to find specifics on configuring Canary Historian, however each includes an OPC HDA Server, and has a Web API that can be used for custom connections. They have a separately licensed ODBC connector to make SQL queries.
Scalability and Performance
Canary is designed to handle large amounts of time-series data. They feature “class leading loss-less data compression” and can scale to over 2 million tags on a single server. If that isn’t enough, cluster multiple Canary Historians for an enterprise solution.
Company Size
Canary labs is a small private company, with less than 50 employees. Such a small company could have difficulties adapting their product quickly based on the customers’ needs.
Cost
Canary has an upfront pricing model. It is based on the number of historian tags, making it a cost-effective solution for smaller deployments. They share their pricing model online without having to enter in an email address or any additional information. It does appear that features such as increased customer support and querying against the Historian will cost extra.
AVEVA Historian (PI Historian)
The AVEVA Historian, formally known as the PI Historian, is a process database. They have existed in the industry for years.
Ease of Configuration
The Historian is highly configurable and can be tailored to fit the specific needs of various industrial applications. It has a wide range of data types, including binary, digital, floating-point, and string, and allows for custom tag configurations, sampling rates, and compression algorithms.
Company Size
AVEVA is a large software company with over 1,200 employees worldwide. Their products page contains over 250 items. Such a range of products could limit their focus, being resistant to adjust or add features for individual customers.
Continuous Improvement and Adaptability
AVEVA has a large ecosystem of partners and developers who build complementary applications and tools around the Historian. In their 2023 Historian brochure, AVEVA shared updates to the Historian Client including, updating the look and feel and creating an interactive editor.
Cost
AVEVA does not share any pricing or model types on their site, you must reach out to a sales representative for a quote.

Evaluate the top alternatives to Processbook & PI Vision in our PI Server Data Visualization Tools Buyer’s Guide.
InfluxDB
InfluxData has a few different database options. One being InfluxDB, an open source, time-series database. They boast fast and secure deployment and setup. With their API, you can query, store, and visualize the data as well.

Easy to Integrate
InfluxDB integrates with a wide range of third-party applications and tools, including, Telegraf, Swift and R. This makes it easy to incorporate InfluxDB into existing workflows and toolchains.
Scalability and Performance
Historically, InfluxData has worked closely with small businesses, though it is designed to handle large-scale time-series data with high performance and scalability. For larger setups, an upgraded version of InfluxDB would be required.
Company Size
InfluxData is the company behind InfluxDB, they are a smaller, private company with about 200 employees. It appears their main customers have also been small businesses.
Continuous Improvement and Adaptability
InfluxData is committed to continuously improving InfluxDB by releasing regular updates that introduce new features and improvements. InfluxData also offers enterprise support services that help customers to customize and optimize their use of InfluxDB.
Other
There are several other time-series databases on the market for third-party applications, each with its own unique strengths and use cases.
TimescaleDB:
This is an open-source relational database designed to handle time-series data. It is built on top of PostgreSQL, which means it has the benefits of a SQL-based database, no need to learn separate coding language. TimescaleDB is fast, claiming it is “7000x faster than InfluxDB”.
Graphite
This is an open-source monitoring tool that includes a time-series database. Their site says Graphite is the “start of a new generation, making it easier to store, retrieve, share and visualize time series data”. Graphite has a large library of available third-part tools and data integrations.
OpenTSDB
This is a distributed, scalable time-series database written in Java. Their data schema is optimized for fast aggregations to minimize storage space. It is a free, downloadable tool through GitHub. Their documentation is available from their website.
Druid
Druid is customizable and can be used for a wide range of use cases, risk analysis, server metric storage, supply chain analytics and digital marketing. They have a Slack and GitHub channel where users can contribute, raise issues, and follow the development. Some have been concerned with security at the openness to modify configuration and more debugging tools are needed.
Final Thoughts on Time-Series Database
When selecting a time-series database for third-party applications, it is essential to select one that offers scalability, high performance, and reliability. Finding a time-series database that is easy to configure and integrate with will lead to faster implementations and happy customers.
Ultimately, the right choice will depend on the specific needs and budget of each organization. Regardless of which option is selected, the right time-series database can help ensure that third-party applications perform optimally, provide actionable insights, and improve decision-making.
Download the Guide
Discover top alternatives to PI’s ProcessBook and PI Vision analytics toolkits.







