In der Prozessindustrie ist die Optimierung der Schlüssel zur Effizienz. Und Effizienz führt zum Gewinn – sie ermöglicht es den Herstellern, mehr zu produzieren und weniger zu verschwenden. Um ihre Prozesse zu optimieren, verwenden viele Hersteller eine Kombination aus Zeitreihen-Daten-Historians und Datenvisualisierungssoftware. dataPARC und PI sind zwei der führenden Unternehmen in diesem Bereich, und in diesem Artikel werden wir dataPARC mit PI vergleichen und einige der Vorteile von dataPARC gegenüber PI als System zum Prozessinformationsmanagement hervorheben.
Sehen Sie sich die Echtzeit-Prozessdatenanalysetools von dataPARC an und erfahren Sie, wie bessere Daten zu besseren Entscheidungen führen können.
dataPARC vs PI: Ähnlichkeiten
dataPARC und PI bestehen seit Jahrzehnten und verfügen über eine große Installationsbasis, die große Hersteller in der ganzen Welt umfasst.
Sowohl dataPARC als auch PI:
- Bieten einen Echtzeit-Daten-Historian
- Verwenden Sie eine binäre, cluster-indexierte, flache Datei zum Speichern der Historie
- Haben Sie eine Asset-Struktur, um die Komplexität von großen unterschiedlichen Datenquellen zu adressieren
- Sie bieten viele der erwarteten Analyse- und Visualisierungstools: Trendbestimmung, Grafiken, Berichte
- Können mit verschiedenen Kontrollsystemen verbunden werden, um Zeitreihendaten in Echtzeit zu erfassen
- Verwenden eine Speicher- und Weiterleitungsfunktion für den Fall, dass die Datenverbindung unterbrochen wird
- Kann mit sehr großen Tag-Count Systemen arbeiten
Gehen wir nun näher auf die Unterschiede ein und sehen wir uns an, wie sich dataPARC von anderen Anbietern unterscheidet.
dataPARC vs PI: Unterschiede
Kosten
Wir können einfach damit beginnen, was eine der wichtigsten Überlegungen bei der Bewertung dieser beiden Daten-Historians und Toolkits zur Prozessdaten-Visualisierung ist.
Langer Rede kurzer Sinn: Die Gesamtbetriebskosten von dataPARC sind im Vergleich zu anderen „ähnlichen“ Branchenlösungen niedriger. Sowohl die Anschaffungskosten als auch die laufenden Kosten sind deutlich niedriger als beim PI-System.
Unbegrenzte Benutzer
Ein wichtiger Grund dafür ist das unbegrenzte Lizenzmodell von dataPARC, das sich hervorragend für Unternehmen eignet, die ihre Produktionsdaten den Entscheidungsträgern auf allen Ebenen des Unternehmens zur Verfügung stellen wollen, ohne sich Gedanken über den Erwerb zusätzlicher Lizenzen machen zu müssen.
PI verwendet ein Preisgestaltungsmodell pro Benutzer. Dieses ist eher für kleine Organisationen mit nur wenigen Mitarbeitern, die auf die Plattform zugreifen, gut geeignet, aber für größere Organisationen oder Unternehmensimplementierung addieren sich die Kosten schnell zusammen.
Mit dataPARC kann jeder, der Zugang zu den Daten benötigt, ohne zusätzliche Kosten darauf zugreifen, so dass jeder Mitarbeiter die Möglichkeit hat, datenbezogene Entscheidungen zu treffen.
Sie suche nach einer Alternative zu PI’s Daten-Historian? Holen Sie sich einen Daten-Historian für Unternehmensdaten zu einem Bruchteil der Kosten. Sehen Sie sich den PARCserver Historian von dataPARC an.
Benutzererfahrung
Wenn Kunden nach den drei bis fünf wichtigsten Vorteilen von dataPARC gefragt werden, steht die Benutzerfreundlichkeit immer ganz oben auf der Liste. Die geringere Komplexität des dataPARC-Systems erlaubt es auch dem weniger „computerbewanderten“ Anwender, mit der Erstellung von Inhalten und der Wertschöpfung zu beginnen, und führt zu einer breiten Akzeptanz der Tools innerhalb einer Organisation.
Obwohl dataPARC viele Funktionen bietet, kann ein neuer Benutzer innerhalb weniger Minuten lernen, wie man nach Tags und Trends sucht und im System navigiert. Von dort aus lernen die Benutzer schnell, dass sie über das Rechtsklickmenü Trendstatistiken anzeigen, Alarmereignisse verwalten, Daten exportieren, Darstellungen wie X/Y-Kurven, Histogramm oder Pareto erstellen können und vieles mehr.
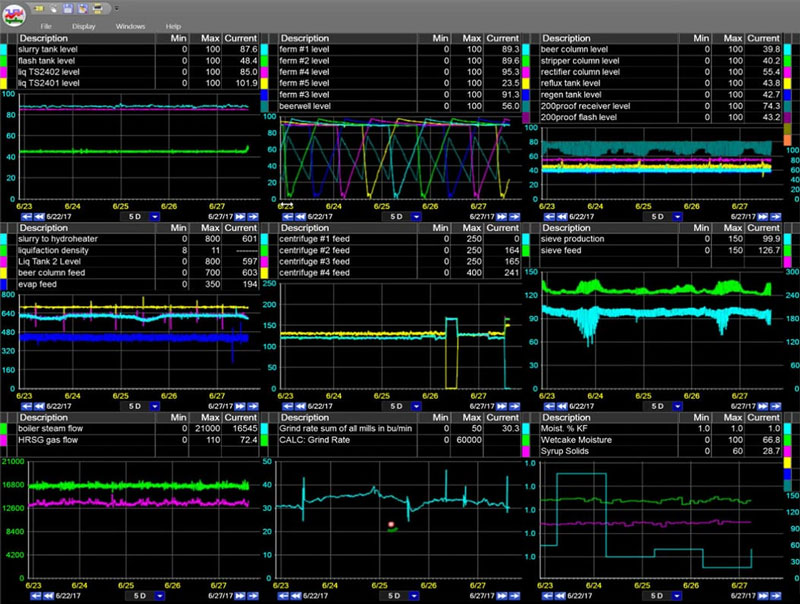
Die Trendbestimmung-Tools von dataPARC werden seit langem von den Kunden als die führende Trendlösung in der Branche anerkannt. dataPARCs Trend-Fähigkeiten sind schneller und weit besser als andere und passen besser in den praktischen Funktionsbereich.
Kein anderes Paket ermöglicht eine schnellere Erstellung einer Trendmatrix, mit schnellem Drag & Drop sowohl vom Tag-Browser als auch von den Anzeigen.
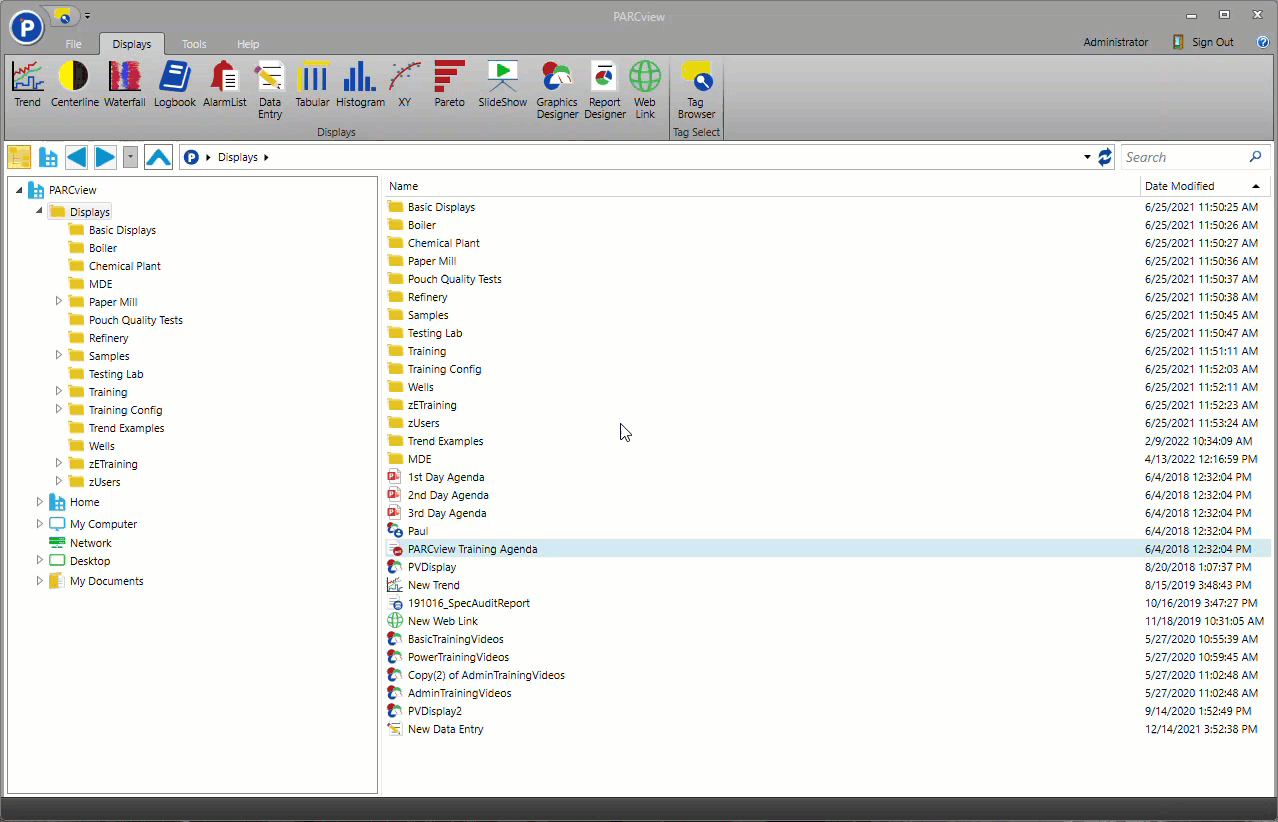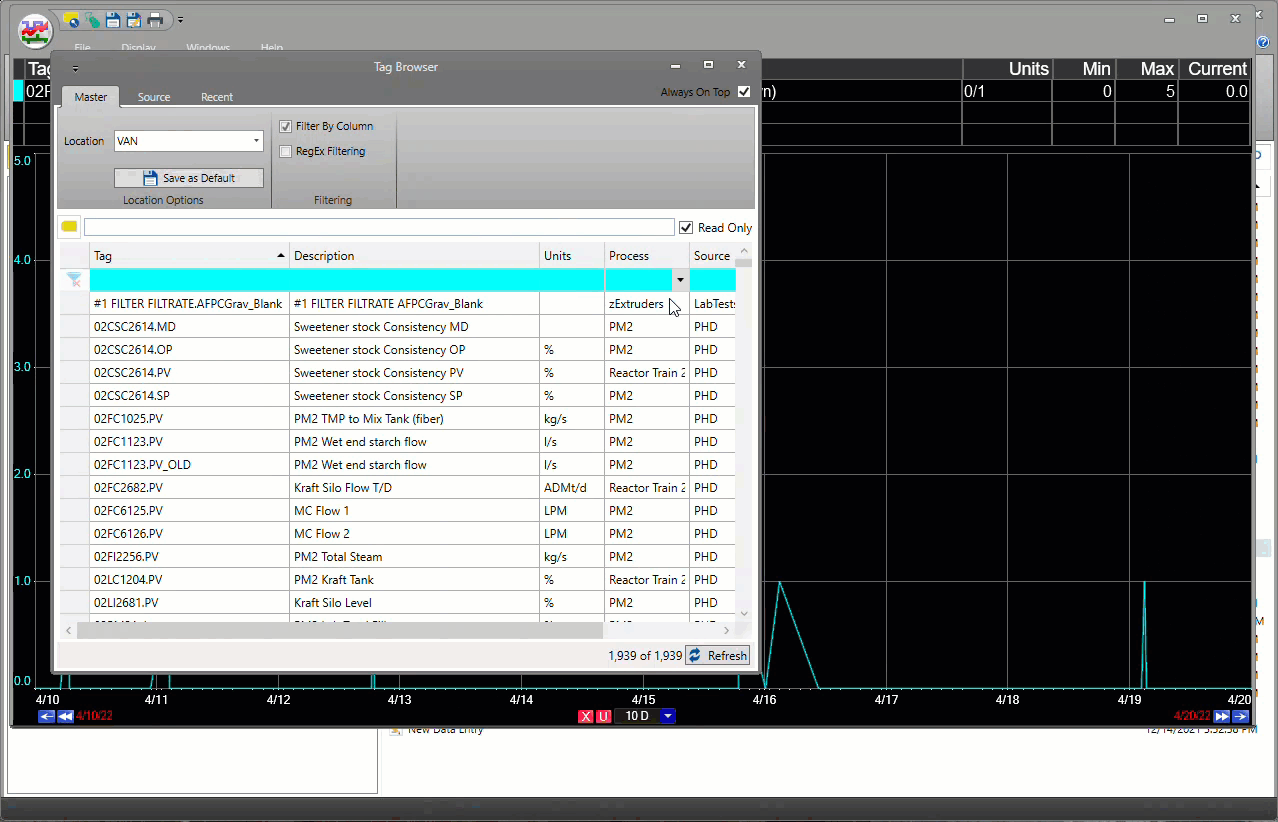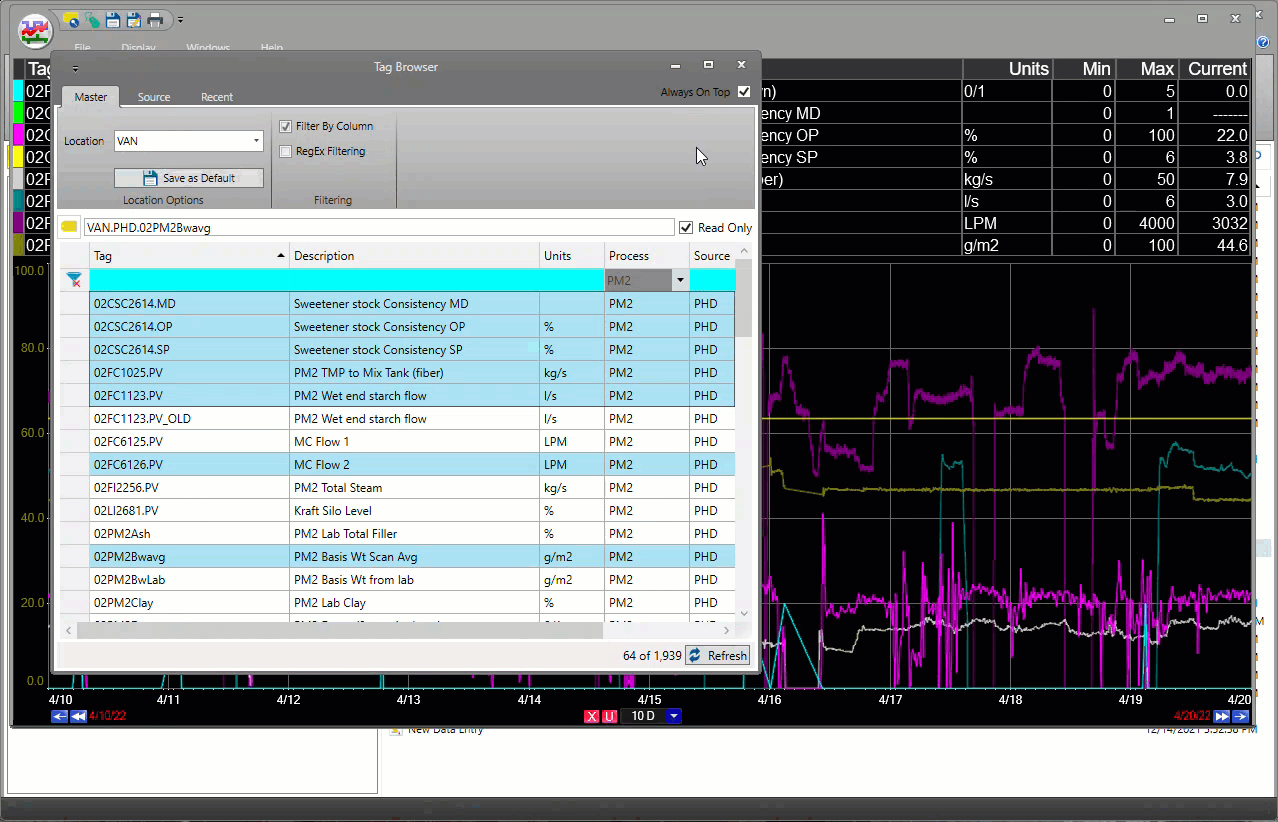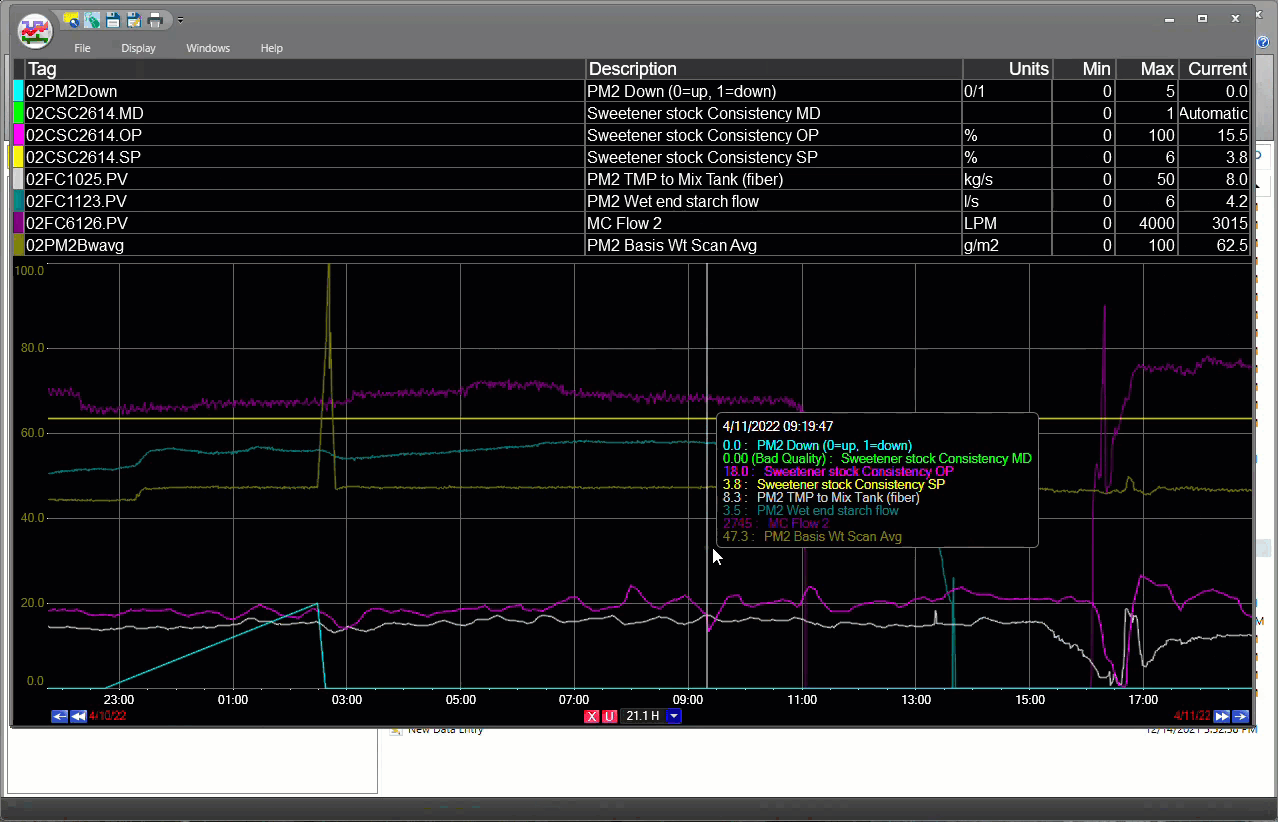
dataPARC macht das Auffinden und Verfolgen von Tag-Daten super-einfach.
Viele Organisationen, die mit dem PI Historian und ProcessBook eingerichtet wurden, haben sich seitdem dafür entschieden, dataPARC einfach für PARCview auf ihre PI Historian „aufsetzen“ zu lassen; die Visualisierungstools und die Bedienungsfreundlichkeit sprechen für sich selbst.
Diagnostische Analytik
Wie bereits erwähnt, gilt dataPARCs Trendbstimmungs-Anwendung als die branchenweit beste. Und das nicht nur wegen der Bedienungsfreundlichkeit und des schnellen Zugriffs auf Analysewerkzeuge, sondern auch wegen der Geschwindigkeit.
Trend
dataPARC verwendet eine gezielte Strategie zur Datengeschwindigkeit mit mehreren Komponenten, einschließlich einer eingebetteten Performance Data Engine (PARCpde), um die Daten schneller zum Benutzer zu bringen. Das Ziel ist es, die „Denkgeschwindigkeit“ des Benutzers zu erreichen und zu übertreffen. PARCpde ist ein grundlegender Bestandteil des gesamten dataPARC-Systems.
Geschwindigkeitstests, die dataPARC vs. PI und andere vorhandene Historians vergleichen, haben gezeigt, dass dataPARC zwischen 10- und 50-mal schneller ist, um große oder langdauernde Datensätze an den Benutzer zurückzuliefern.
Mehrere Unternehmen haben zum Teil wegen der Datengeschwindigkeit auf dataPARC umgewechselt. dataPARC nutzt in seiner Architektur auch ein Aggregat- und ein Rollup-Archiv, was den Zeitaufwand bei der Lösung von Problemen oder der Untersuchung von Möglichkeiten erheblich reduziert.
Aus dem Trend können Benutzer ein schnelles Statistikraster starten und ein neues X/Y-Diagramm oder eine Histogrammanzeige generieren. Jedes Diagramm zieht die Tags aus dem Trend, so dass die Benutzer nicht mehr im Tag Browser danach suchen müssen.
Das X/Y-Diagramm richtet zwei Tags zum Vergleich ein, und es kann eine Best-Fit-Linie erstellt werden – linear, polynomisch usw. Die aus der Anpassung generierte Formel kann in einen Trend oder eine andere Anzeige übernommen werden. PI kann ebenfalls X/Y-Diagramme erzeugen, aber sie werden von Grund auf neu erstellt und es wird keine Best-Fit-Linie erzeugt.
Excel-Zusatzmodul
Das Excel Add-in von dataPARC wurde für hohe Bedienungsfreundlichkeit und Geschwindigkeit geschrieben.
PI’s PI DataLink und dataPARC verfügen beide über In-Cell-Funktionen, die Daten direkt in Excel ziehen können. Das Add-in von dataPARC hat mehrfache andere Funktionen.
Es gibt ein Arbeitsblatt, das mehrere Tags im gleichen Zeitbereich abrufen kann, ohne mit Formeln zu arbeiten. Benutzer können Tag-Listen aus bereits erstellten dataPARC-Anzeigen importieren, anstatt die Tags erneut zu suchen.
Neben dem Wert, der durch die Tools der vorhandenen Excel Add-ins gewonnen wird, zeichnen sich die von dataPARC durch folgendes aus:
- Ziehen von Gruppen von Tags/Daten aus mehreren Datenquellen in Excel
- Filtern von Daten auf der Grundlage von Werten mehrerer Tags
- Erstellen von Kreuzkorrelation/R2-Matrix
- CUSUM- und MSR-Diagrammerstellung
Darüber hinaus können Benutzer zeitreihen-basierte Daten aus Excel in PARCview Trends und Anzeigen darstellen. Auf diese Weise lassen sich neben den Prozessdaten auch Trends oder Vergleiche mit unternehmensexternen Daten erstellen.

Bewerten Sie die besten Alternativen zu ProcessBook & PI Vision in unserem PI Server Data Visualization Tools Buyer’s Guide.
Betriebsmanagement
Betriebsmanagement in Echtzeit ist notwendig, um eine Produktionsstätte mit höchster Effizienz zu betreiben und um schnell auf Prozessausschläge reagieren zu können, die zu ungeplanten Ausfallzeiten oder Produktverlusten führen.
Dies wird von dataPARC in vielfältiger Weise unterstützt:
- Grafische Prozessdarstellungen
- KPI- und Labordaten-Dashboards
- Tools für manuelle Dateneingabe (MDE)
- Automatisierte Berichterstattung
- Prozessalarme und Benachrichtigungen
- und mehr
Beim Vergleich von dataPARC und PI bieten beide die Möglichkeit, dynamische, informationsreiche grafische Dashboards zu erstellen, aber nur dataPARC verfügt über die Mittellinienanzeige.
Mittellinie
Mittellinie ist ein leistungsfähiges Überwachungswerkzeug, das es nur bei dataPARC gibt. Es ist eine Echtzeit-Darstellung, die Statistiken für Tags ausführt. Die Durchläufe können grad- oder zeitbasiert sein, und die Statistiken umfassen Zeitmittelwert, Standardabweichung, CpK, Minimum, Maximum usw.
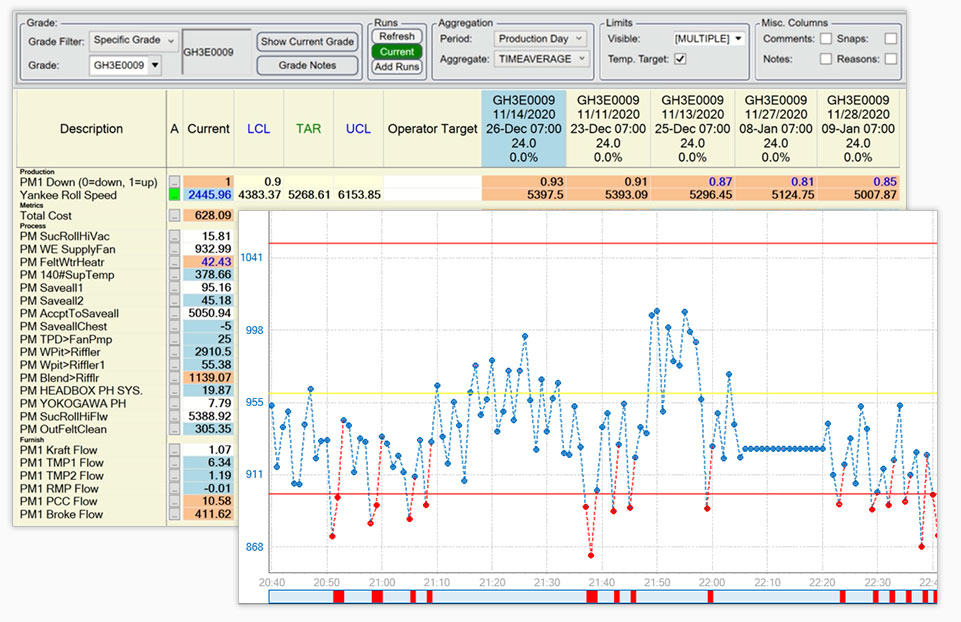
Die Funktion Mittellinie zeigt Daten für Zeiträume oder Durchläufe an, um sicherzustellen, dass die Prozessbedingungen nach dem Durchlauf gleich sind.
Die Mittellinienanzeige soll dabei helfen, die besten Betriebseinstellungen für die Produktion zu bestimmen und sicherzustellen, dass diese Einstellungen normalerweise während der Produktion verwendet werden.
Mittellinie ist eines der leistungsstarken Datenanalyse-Tools von dataPARC, für das es kein Gegenstück in PI gibt.
Alarme und Benachrichtigungen
Das Alarm- und Benachrichtigungssystem von dataPARC kann E-Mails und Textbenachrichtigungen versenden oder Arbeitsabläufe auslösen, wenn ein Alarm erkannt oder beendet wird. Sobald ein Alarm erkannt wird, wird ein Alarmereignis erstellt. Diese Ereignisse können in einer Trend-, Mittellinien-, Grafik- oder Alarmliste angezeigt und quittiert werden. Benutzer können das Ereignis quittieren, indem sie einen Grund aus dem Ursachenbaum zuweisen und/oder einen Kommentar zum Ereignis eingeben. Eine schnelle Analyse kann in dataPARC mit dem Pareto-Diagramm durchgeführt werden, um die wichtigsten für einen Alarm gespeicherten Gründe zu ermitteln oder einen tabellarischen Bericht zu erstellen, der nach Gründen sortiert ist und alle Kommentare sichtbar macht.
Ebenso können PI-Benachrichtigungen Ereignisrahmen erstellen und Benachrichtigungen versenden. Sobald Ereignisrahmen erkannt wurden und ein Grund zugewiesen wurde, können Benutzer diese Daten als Tabelle in PI Vision sehen, aber weitere Analysen oder Berichte müssen bei PI mit dem Excel Add-in DataLink durchgeführt werden. Das Excel Add-in von dataPARC verfügt ebenfalls über Funktionen zur Erfassung von Alarmereignisdaten.
Weitere dataPARC Excel Add-in-Funktionen werden im folgenden Abschnitt näher untersucht.
Manuelle Dateneingabe (MDE)
Die MDE-Anzeige von dataPARC lässt sich schnell konfigurieren und ermöglicht es den Benutzern, manuelle Daten in die Datenbank einzugeben und zu speichern, anstatt sie auf einem Blatt Papier oder in Excel zu notieren.
Manuell eingegebene Daten werden durch Tags dargestellt, so dass sie wie jedes andere Tag in PARCview-Trends, Dashboards und Displays verwendet werden können.
Müssen Sie Ihren Prozessingenieuren bessere Daten zur Verfügung stellen? Sehen Sie sich unsere Echtzeit-Prozessdatenanalysetools an und erfahren Sie, wie bessere Daten zu besseren Entscheidungen führen können.
Berechnungen
Wenn die Benutzer nicht über das perfekte Tag für die Verwaltung eines Prozesses verfügen, wird häufig ein Calc-Tag oder MDE verwendet. Sowohl dataPARC als auch PI können einfache Berechnungen wie das Hinzufügen von Tags, Wenn/Dann-Anweisungen oder Einheitenumrechnungen durchzuführen.
Mit PI Vision unterstützt PI Analytics keine VB-Skripte mehr. VB-Skripting öffnet die Türen für kundenspezifische Lösungen und dataPARC nutzt VB-Skripting für Anwendungen wie Datenbanklesen, Dateianalyse, Webservice-Aufrufe und vieles mehr.
Asset-Modellierung
Sowohl der Asset Hub von dataPARC als auch das Asset Framework (AF) von PI bieten Möglichkeiten, Zeitreihendaten zu strukturieren und zu kontextualisieren, indem Tags um physische Assets herum organisiert werden. PI AF ist zwar leistungsstark, erfordert jedoch häufig eine komplexere Konfiguration unter Verwendung externer Tools und Skripte. Im Gegensatz dazu wurde Asset Hub speziell für Ingenieure und Betreiber entwickelt und bietet eine intuitivere Point-and-Click-Oberfläche zum Erstellen und Verwalten von Asset-Hierarchien, ohne dass eine spezielle Schulung erforderlich ist.
Was Asset Hub auszeichnet, ist seine enge Integration mit den Trend-, Dashboard- und Alarmtools von dataPARC. Benutzer können schnell von der Gesamtansicht der Anlage zu einzelnen Assets navigieren und Echtzeit-KPIs, historische Trends und Leistungsgrenzen an einem Ort anzeigen.
Webzugriff und Flexibilität
Was den Webzugriff angeht, sind PI-System-Benutzer auf PI Vision beschränkt, ein vollständig webbasiertes Tool. Es bietet zwar eine zentralisierte Möglichkeit zur Anzeige von Daten, verfügt jedoch nicht über eine Desktop-Entsprechung, was für Benutzer, die eine robustere, lokal installierte Anwendung bevorzugen oder benötigen, einschränkend sein kann. Einige der Mängel wurden bereits in den vorangegangenen Abschnitten angesprochen, darunter auch Berechnungen.
dataPARC bietet sowohl eine voll funktionsfähige Desktop-Anwendung (PARCview) als auch eine browserbasierte Version. Dieser hybride Ansatz gibt Teams die Flexibilität, das beste Tool für die jeweilige Aufgabe auszuwählen, egal ob sie sich im Kontrollraum befinden, an einem Laptop arbeiten oder remote tätig sind.
Vorhersagende Analytik
PARCmodel von dataPARC bietet ein gewisses Maß an prädiktiver Analyse mit den Modellierungsfunktionen PLS (Partial Least Square) und PLC (Principal Component Analysis).
PLS
Das PLS-Paket wurde von einem der weltweit führenden praktischen Modellierern als „…unvergleichlich, einfach besser als alles, was ich je gesehen habe“, beschrieben. In der Prozessindustrie ist eine der Anwendungen für die PLS-Modellierung der Bau von inferentiellen Eigenschaftsprädiktoren (IPPs).
Kontrollingenieure in Betriebsfirmen berichten, dass eine PLS-Modellgenerierung für ein IPP mehr als 8 Stunden dauern kann (länger für das ursprüngliche Modell), wenn mehrere Tools und Offline-Aktivitäten verwendet werden. dataPARC integriert dies alles in einem Tool, und der Umbauaufwand kann so kurz wie 5 Minuten sein.
Diese patente Modellerstellung ermöglicht es, mehrere Lösungen zu generieren, um die beste Option zu finden. Die Geschwindigkeit der Umgestaltung ermöglicht eine breitere Anwendung und besseren Nutzen von PLS. Praktische Engineering-Methoden und sogar Prozess-„Intuitionen“ können jetzt mit einer schnellen Validierung durch eine mathematische PLS-Sitzung in zwei bis fünf Minuten unterstützt werden.
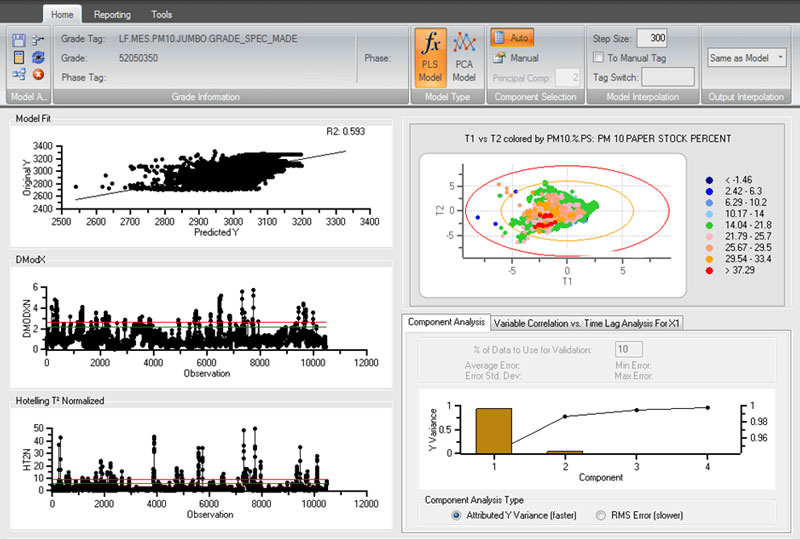
Tools für die prädiktive Modellierung von dataPARC
dataPARC bietet enorme Zeiteinsparungen, eine bessere Lernumgebung, eine bessere Umgebung für die Zusammenarbeit und nützlichere Anwendungen – all dies verbessert den Mehrwert für die wichtigsten Geschäftsfaktoren des Unternehmens.
PCA
PCA nutzt die gleichen Modellierungsvorteile wie das PLS von dataPARC, was eine einfache Modellgenerierung ermöglicht. Der Unterschied zwischen den beiden Modellierungsmethoden besteht darin, dass PLS versucht, eine einzelne Variable zu modellieren und nachzuahmen, indem benachbarte Variablen als Modelleingaben verwendet werden. PCA dagegen modelliert keine einzelne Variable, sondern einen ganzen Prozess.
Der Wert ergibt sich beim Vergleich des aktuellen Prozesses mit dem modellierten Prozess. PCA gibt dem Benutzer die Möglichkeit, zu wissen, wann der aktuelle Prozess inaktiv ist (im Vergleich zum modellierten Prozess) und identifiziert die „störende(n)“ Prozessvariable(n).
PCA nutzt zwei Parameter (auch für das PLS-Modell verfügbar): DMODX (Fehler vom Modell) und HT2N (Hotellingsche T-Quadrat-Verteilung – Abweichungsnorm). Die Eingangsvariablen im PCA-Modell sind alle gegradigt und das Personal kann sehen, welche Variable(n) das Problem verursachen. PCA kann als Frühwarnsystem verwendet werden, um Bedienern zu helfen, ein Problem zu erkennen, bevor es passiert.
PARCmodel ist separat lizenziert, aber in PARCview integriert und kann einfach über das Trend-Rechtsklick-Menü aufgerufen werden. PI verfügt über keine ähnlichen Analysetools.
Sie möchten ProcessBook ersetzen Sehen Sie, warum PARCview als die führende ProcessBook-Alternative betrachtet wird.
Kundenorientierte Entwicklung und Support
Bei dataPARC stehen der Kunde und seine realen, zeitnahen und praktischen Bedürfnisse an erster Stelle. Die Strategie von dataPARC beinhaltet eine hohe Aufmerksamkeit auf die Bedürfnisse des Kunden und schnelle Problemlösung.
dataPARC beschäftigt viele SME, die in wichtigen Rollen der Prozessunterstützung für operative Unternehmen der Branche tätig sind. Im Laufe der Jahre wurden die Benutzerfunktionen und die gesamte Systemarchitektur von dataPARC von den SME und Kunden geprägt. dataPARC wird von Endbenutzern für Endbenutzer entwickelt.
Bei dataPARC verkaufen wir mehr als nur Software, wir verkaufen unsere Dienstleistungen, um Trends, Grafiken und andere Displays zu erstellen, damit Ihr System sofort richtig läuft. Unsere Ingenieure und Support-Mitarbeiter stehen zur Verfügung, um neue Projekte zu implementieren und kontinuierliche Unterstützung zu bieten.
Mit PI müssten die Kunden, um dieselben Displays zu erstellen, die Aufgabe an einen Drittanbieter auslagern. dataPARC bietet alles aus einer Hand.
Schlussfolgerung
dataPARC und PI haben viel gemeinsam, aber dataPARC hat die Oberhand, wo es darauf ankommt – Benutzererfahrung, Geschwindigkeit der Daten und Kosten. dataPARC ist einfach, schnell und effektiv.
Die Vorteile von dataPARC vs PI wachsen mit jeder neuen Funktion und jedem Update weiter. Funktionen, die von Benutzern und Kunden gesteuert werden.
Laden Sie den Guide herunter
Entdecken Sie die besten Alternativen zu den PI-Analyse-Toolkits ProcessBook und PI Vision.







