Nas indústrias de processo, a otimização é a chave para a eficiência. E a eficiência é o que leva ao lucro – permitindo que os fabricantes produzam mais e desperdicem menos. Para otimizar seus processos, muitos fabricantes usam uma combinação de historiador de dados de séries temporais e software de visualização de dados. dataPARC e PI são dois dos líderes neste espaço e, neste artigo, compararemos dataPARC vs PI e destacaremos algumas das vantagens que dataPARC tem sobre PI como um sistema de gerenciamento de informações de processo.
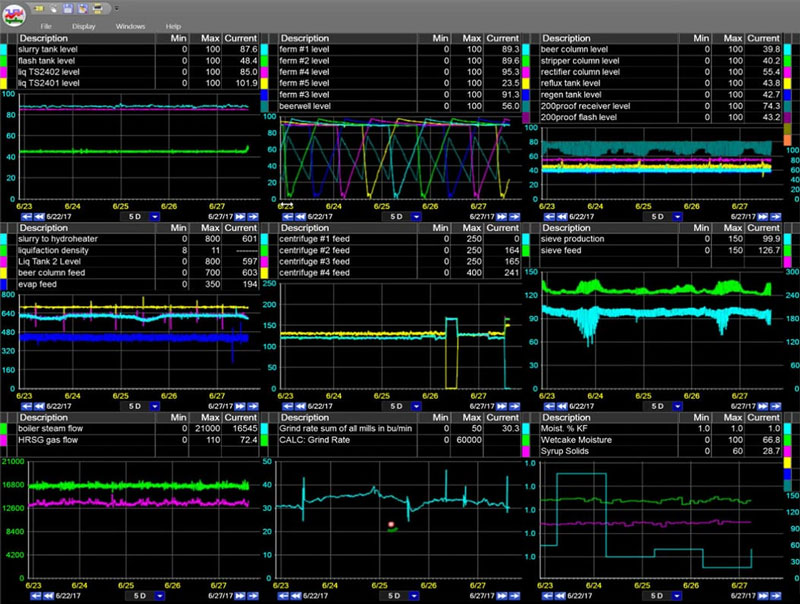
Confira as ferramentas de análise de dados de processo em tempo real do dataPARC e veja como dados melhores podem levar a melhores decisões.
dataPARC vs PI: Semelhanças
dataPARC e PI existem há décadas e têm grandes bases de instalação representadas por grandes fabricantes ao redor do mundo.
Tanto o dataPARC quanto o PI:
- Oferecem um historiador de dados em tempo real
- Usam um arquivo binário, cluster-index, simples para armazenar o histórico
- Têm uma estrutura de ativos para lidar com as complexidades de grandes fontes de dados díspares
- Oferecem muitas das ferramentas de análise e visualização esperadas: tendências, gráficos, relatórios
- Podem se conectar a vários sistemas de controle para coletar dados de séries temporais em tempo real
- Usam uma função de armazenar e encaminhar caso a conectividade de dados seja perdida
- Podem trabalhar com sistemas de contagem de tags muito grandes
Agora, vamos nos aprofundar mais em suas diferenças e ver como o dataPARC se diferencia.
dataPARC vs PI: Diferenças
Custo
Podemos começar com o que será uma das principais considerações ao avaliar esses dois kits de ferramentas de visualização de dados de processo e historiador de dados.
Resumindo, o custo total de propriedade do dataPARC é menor quando comparado a outras soluções “semelhantes” do setor. Tanto o custo inicial quanto os custos contínuos são consideravelmente menores do que o PI System.
Usuários ilimitados
Um dos principais motivos para isso é o modelo de licença ilimitada do dataPARC, que o torna uma ótima opção para organizações que desejam obter dados de produção na frente dos tomadores de decisão em todos os níveis da planta sem se preocupar em ter que comprar licenças adicionais.
O PI usa um modelo de preços por usuário. Isso tende a funcionar para pequenas organizações com apenas algumas pessoas precisando acessar a plataforma, mas para organizações maiores ou implementações empresariais o custo aumenta rapidamente.
Com o dataPARC, todos que precisam de acesso aos dados podem ter acesso sem custo adicional – colocando o poder de tomar decisões de dados nas mãos de cada funcionário.
Procurando uma alternativa ao Historiadores de Dados do PI? Obtenha um historiador de dados de planta empresarial por uma fração do custo. Confira o historiador PARCserver do dataPARC.
Experiência do usuário
Quando os clientes são questionados sobre os 3 a 5 principais benefícios do dataPARC, a facilidade de uso está sempre no topo da lista. A complexidade reduzida do sistema dataPARC permite que até mesmo a pessoa menos “experiente em computadores” comece a criar conteúdo e ganhar valor, e resulta em ampla adoção das ferramentas dentro de uma organização.
Embora existam muitos recursos no dataPARC, um novo usuário pode aprender a pesquisar tags, tendências e navegar em minutos. A partir daí, os usuários aprendem rapidamente que podem visualizar estatísticas de tendências, gerenciar eventos de alarme, exportar dados, criar exibições como X/Y Plot, Histograma ou Pareto e muito mais, tudo a partir do menu do botão direito.
As ferramentas de tendências do dataPARC são reconhecidas há muito tempo pelos clientes como a solução de tendências número 1 do setor. Os recursos de tendências do dataPARC são mais rápidos e muito superiores aos outros e se encaixam melhor no reino da função prática.
Nenhum outro pacote permite uma construção mais rápida de uma matriz de tendências, com arrastar e soltar rápido do navegador de tags e exibições.
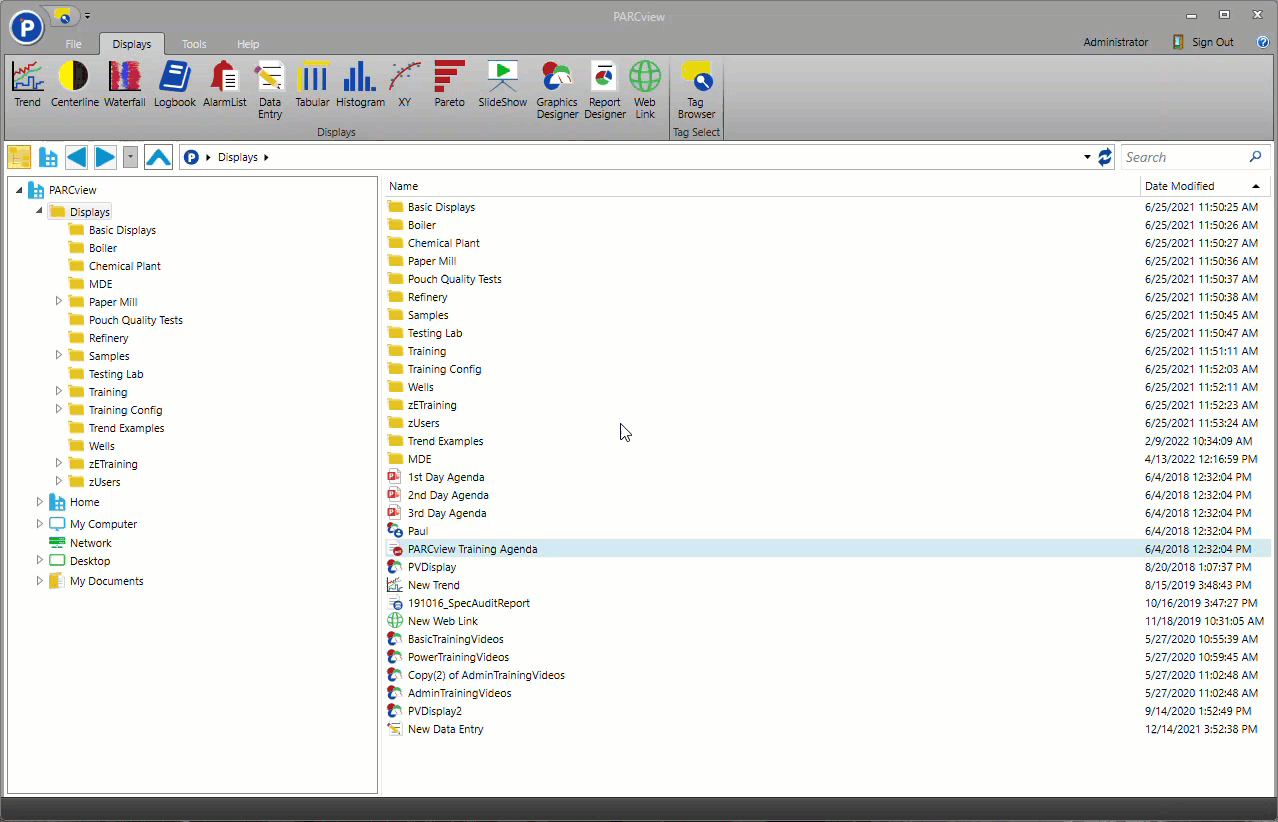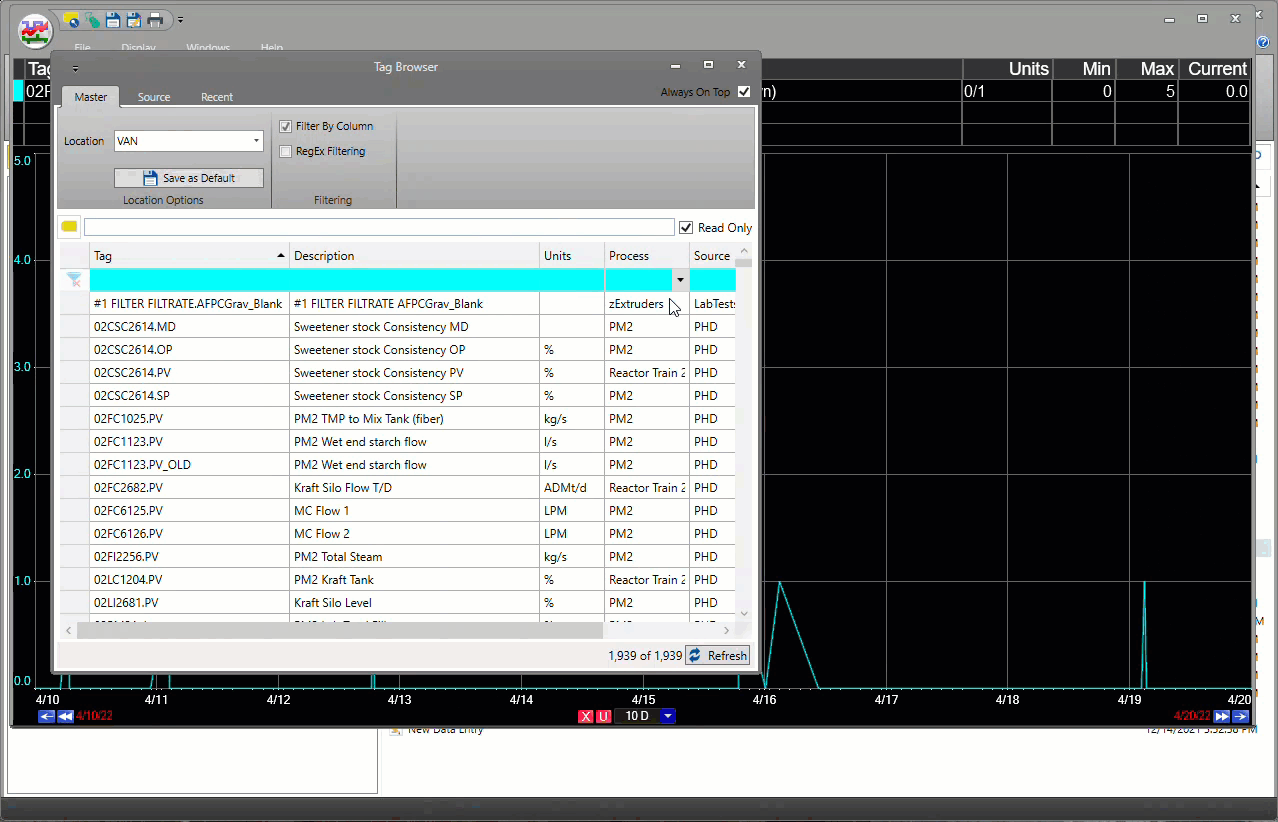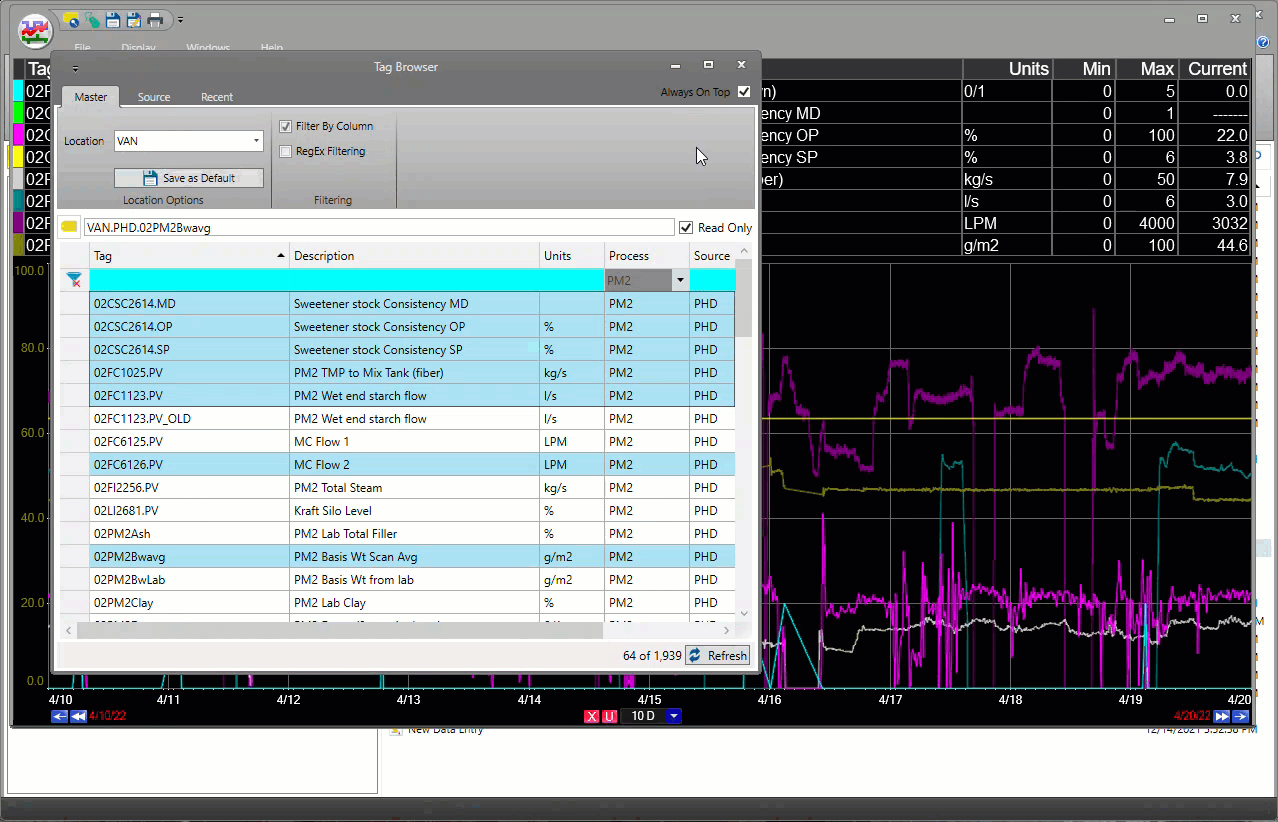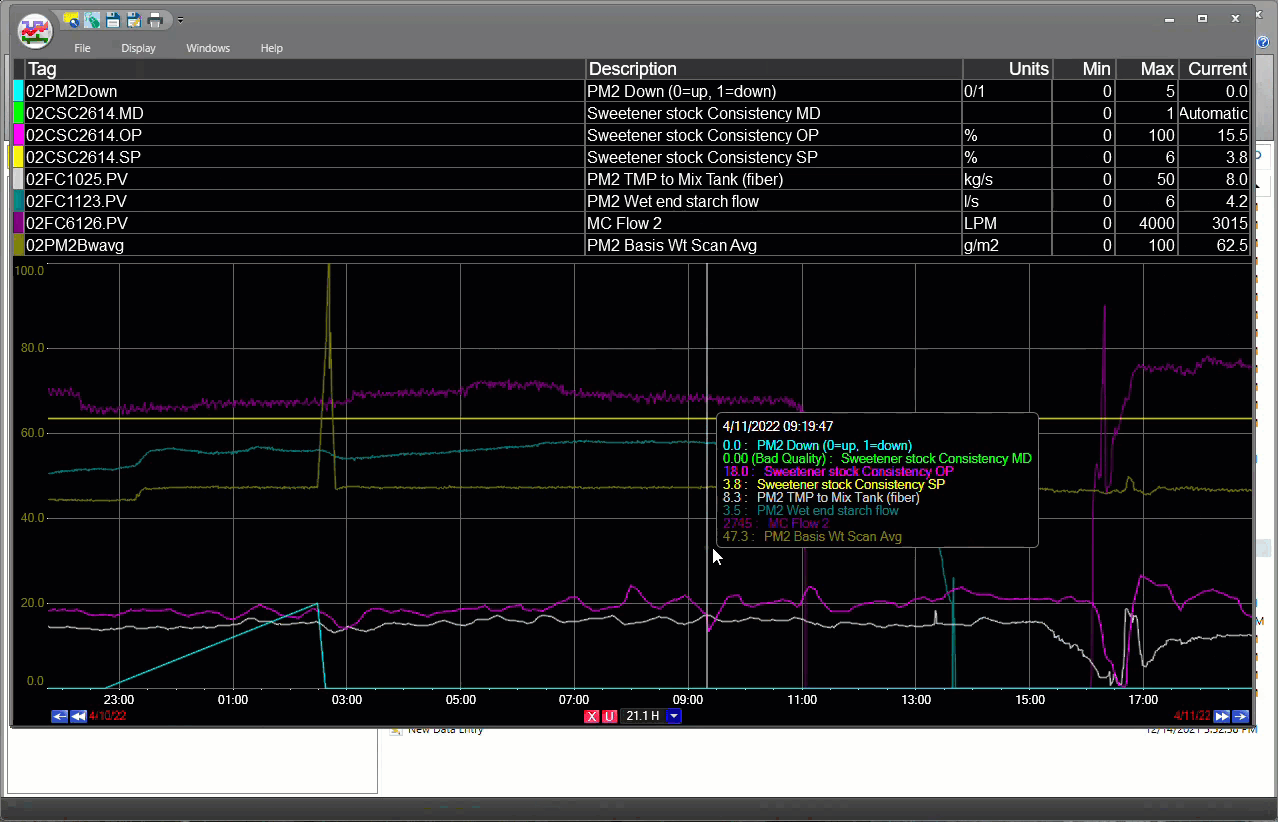
O dataPARC torna a localização e a tendência de dados de tags superfáceis.
Muitas organizações que foram configuradas com o PI Historian e o ProcessBook escolheram fazer com que o dataPARC “ficasse no topo” do seu PI historian simplesmente para o PARCview; as ferramentas de visualização e a facilidade de uso falam por si.
Análise de diagnóstico
Como mencionado anteriormente, o aplicativo de tendências do dataPARC é considerado o melhor do setor. Não apenas por sua facilidade de uso e acesso rápido às ferramentas de análise, mas também por sua velocidade.
Tendência
O dataPARC usa uma estratégia deliberada de velocidade de dados com vários componentes, incluindo um Performance Data Engine (PARCpde) incorporado para acelerar os dados para o usuário. O objetivo é atender e exceder a “velocidade de pensamento” do usuário. O PARCpde é uma parte fundamental de todo o sistema dataPARC.
Testes de velocidade comparando o dataPARC com o PI e outros historiadores contemporâneos mostraram que o dataPARC é de 10X a 50X mais rápido na entrega de conjuntos de dados grandes ou de longo prazo de volta ao usuário.
Várias empresas mudaram para o dataPARC em parte por causa da velocidade dos dados. O dataPARC também utiliza um arquivo agregado e um arquivo rollup em sua arquitetura, o que reduz muito a quantidade de tempo desperdiçado ao resolver problemas ou investigar oportunidades.
A partir da tendência, os usuários podem iniciar uma grade de estatísticas rápida, gerar um novo gráfico X/Y ou exibição de histograma. Cada gráfico extrairá as tags da tendência, para que os usuários não precisem procurá-las no Navegador de tags novamente.
O gráfico X/Y define duas tags para comparação e uma linha de melhor ajuste pode ser gerada – linear, polinomial, etc. A fórmula gerada a partir do ajuste pode ser extraída para uma tendência ou outra exibição. O PI também pode gerar gráficos X/Y, mas eles são criados do zero e nenhuma linha de melhor ajuste é gerada.
Suplemento do Excel
O suplemento Excel do dataPARC foi criado com um alto grau de facilidade de uso e velocidade.
O PI PI DataLink e o dataPARC têm funções na célula que podem extrair dados diretamente para o Excel. O suplemento dataPARC tem várias outras funções.
Há uma planilha que pode extrair várias tags no mesmo intervalo de tempo sem lidar com fórmulas. Os usuários podem importar listas de tags de exibições dataPARC já criadas em vez de procurar as tags novamente.
Além do valor obtido em ferramentas de complemento do Excel legadas, o dataPARC é destacado pelo seguinte:
- Arraste grupos de tags/dados para o Excel de várias fontes de dados
- Filtre dados com base em vários valores de tags
- Geração de matriz de correlação cruzada/R2
- Gráficos CUSUM e MSR
Além disso, os usuários podem exibir dados baseados em séries temporais do Excel em tendências e exibições do PARCview. Isso pode ser usado para tendências ou comparar dados de fora da empresa ao lado dos dados do processo.

Avalie as principais alternativas ao ProcessBook e ao PI Vision em nosso PI Server Data Visualization Tools Buyer’s Guide.
Gerenciamento de operações
O gerenciamento de operações em tempo real é necessário para manter uma planta funcionando com eficiência máxima e para poder responder rapidamente a excursões de processo que resultam em tempo de inatividade não planejado ou perda de produto.
Isso é facilitado pelo dataPARC de várias maneiras:
- Exibições gráficas de processo
- Painéis de KPI e dados de laboratório
- Ferramentas de entrada manual de dados (MDE)
- Relatórios automatizados
- Alarmes e notificações de processo
- e mais
Ao comparar o dataPARC com o PI, ambos oferecem a criação de painéis gráficos dinâmicos e repletos de informações, mas apenas o dataPARC tem a exibição da linha central.
Linha central
Linha central é uma poderosa ferramenta de monitoramento exclusiva do dataPARC. É uma exibição em tempo real que relata estatísticas baseadas em execução para tags. As execuções podem ser baseadas em Grau ou Tempo, e as estatísticas incluem média de tempo, desvio padrão, CpK, mínimo, máximo, etc.
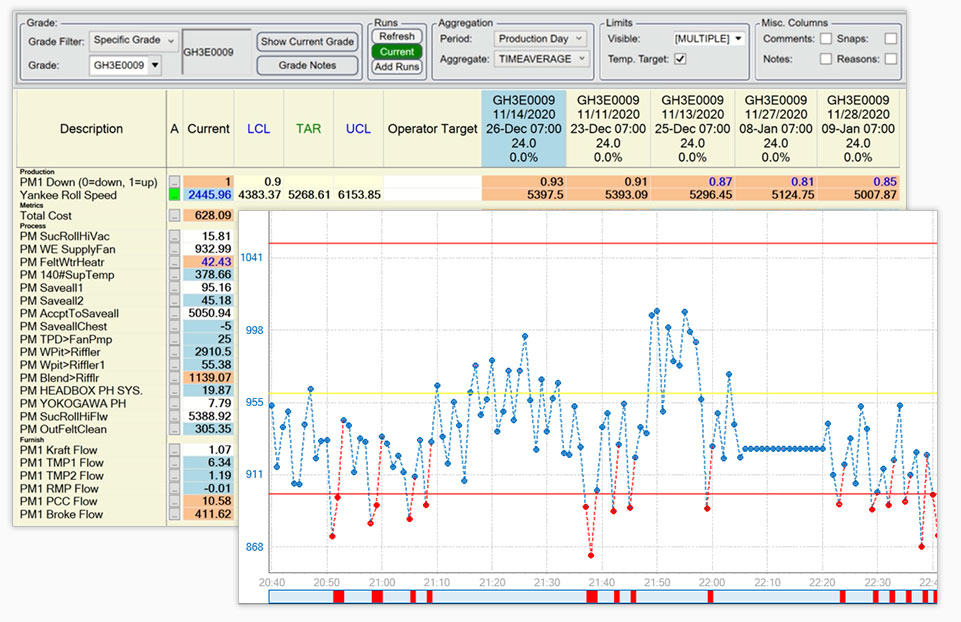
Linha central exibe dados para períodos de tempo ou execuções para garantir que as condições do processo sejam as mesmas execução após execução.
O objetivo de uma exibição da linha central é ajudar a determinar as melhores configurações operacionais para produção e garantir que essas configurações sejam normalmente usadas durante a produção.
Linha central é uma das poderosas ferramentas de análise de dados do dataPARC para a qual não há equivalente PI.
Alarmes e notificações
O sistema de alarme e notificação do dataPARC pode enviar e-mails, notificações de texto ou acionar fluxos de trabalho quando um alarme é detectado ou fechado. Uma vez que um alarme é detectado, um evento de alarme é criado. Esses eventos podem ser visualizados e reconhecidos em uma tendência, linha central, gráfico ou lista de alarmes. Os usuários podem reconhecer o evento atribuindo um motivo da árvore de motivos e/ou digitando um comentário para o evento. Uma análise rápida pode ser feita no dataPARC com o gráfico de Pareto para determinar os principais motivos salvos para um alarme ou criar um relatório tabular classificado por motivo com todos os comentários visíveis.
Da mesma forma, as notificações PI podem criar estruturas de eventos e enviar notificações. Uma vez que os quadros de eventos são detectados e um motivo atribuído, os usuários podem ver esses dados como uma tabela no PI Vision, mas análises ou relatórios adicionais são necessários para ocorrer no PI Suplemento Excel DataLink. O Suplemento Excel do dataPARC também tem recursos para extrair dados de eventos de alarme.
Mais recursos do dataPARC Suplemento Excel são explorados na seção a seguir.
Entrada Manual de Dados (MDE)
A exibição MDE do dataPARC é rápida de configurar e permite que os usuários insiram e salvem dados manuais no banco de dados em vez de em um pedaço de papel ou no Excel.
Os dados inseridos manualmente são representados por tags, portanto, podem ser usados em tendências, painéis e exibições do PARCview como qualquer outra tag.
Precisa colocar melhores dados nas mãos de seus engenheiros de processo? Confira nossas ferramentas de análise de processos em tempo real e veja como dados melhores podem levar a melhores decisões.
Cálculos
Quando os usuários não têm a tag perfeita para ajudar a gerenciar um processo, uma tag calc ou MDE é frequentemente usada. O dataPARC e o PI são capazes de executar cálculos simples, como adicionar tags, instruções If/Then ou conversões de unidades.
Com o PI Vision, o PI Analytics não suporta mais scripts VB. O script VB abre as portas para soluções personalizadas e o dataPARC aproveita o script VB para aplicativos como leituras de banco de dados, análise de arquivos, chamadas de serviços da Web e muito mais.
Modelagem de ativos
Tanto o Asset Hub da dataPARC quanto o Asset Framework (AF) da PI oferecem maneiras de estruturar e contextualizar dados de séries temporais, organizando tags em torno de ativos físicos. Embora o PI AF seja poderoso, muitas vezes requer uma configuração mais complexa usando ferramentas externas e scripts. Em contrapartida, o Asset Hub foi projetado especificamente para engenheiros e operadores, oferecendo uma interface mais intuitiva do tipo apontar e clicar para criar e gerenciar hierarquias de ativos sem a necessidade de treinamento especializado.
O que diferencia o Asset Hub é sua forte integração com as ferramentas de tendências, painéis e alarmes do dataPARC. Os usuários podem navegar rapidamente da visão geral da planta para ativos individuais e visualizar KPIs em tempo real, tendências históricas e limites de desempenho em um único lugar.
Acesso à web e flexibilidade
Quando se trata de acesso à web, os usuários do PI System estão limitados ao PI Vision, uma ferramenta totalmente baseada na web. Embora forneça uma maneira centralizada de visualizar dados, ele não possui uma versão para desktop, o que pode ser limitante para usuários que preferem ou precisam de um aplicativo mais robusto instalado localmente. Algumas das deficiências foram expressas nas seções anteriores, incluindo cálculos.
O dataPARC oferece um aplicativo de desktop completo (PARCview) e uma versão baseada em navegador. Essa abordagem híbrida oferece às equipes a flexibilidade de escolher a melhor ferramenta para a tarefa, estejam elas na sala de controle, em um laptop ou trabalhando remotamente.
Análise Preditiva
O PARCmodel do dataPARC oferece um grau de análise preditiva com capacidades de modelagem PLS (Partial Least Square) e PLC (Principal Component Analysis).
PLS
O pacote PLS foi descrito por um dos principais engenheiros de modelagem prática do mundo como “…incomparável, melhor do que qualquer coisa que eu já vi antes”. Na indústria de processamento, uma das aplicações para modelagem PLS é na construção de preditores de propriedade inferencial (IPPs).
Engenheiros de controle em empresas operacionais relatam que uma geração de modelo PLS para um IPP pode levar mais de 8 horas para remodelar (mais tempo para o modelo inicial) usando várias ferramentas e atividade off-line. O dataPARC integra tudo em uma ferramenta e o esforço de remodelação pode ser de apenas 5 minutos.
Essa geração rápida de modelo permite que várias soluções sejam geradas para comparação para encontrar a melhor opção. A velocidade da remodelação permite uma aplicação e benefício mais amplos do PLS. Métodos práticos de engenharia e até mesmo “palpites” de processo agora podem ser apoiados com uma validação rápida por uma sessão matemática do PLS em 2 a 5 minutos.
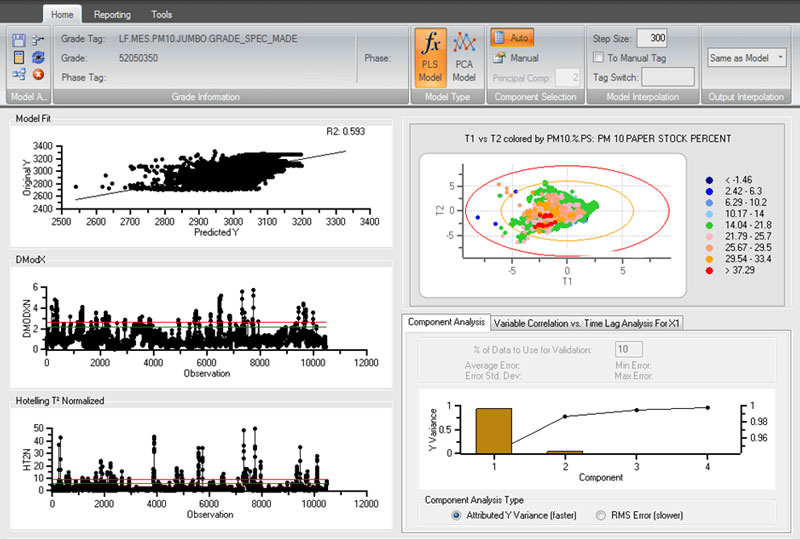
Ferramentas de modelagem preditiva do dataPARC
O dataPARC oferece grande economia de tempo, melhor ambiente de aprendizagem, melhor ambiente de colaboração, aplicativos mais úteis — tudo isso acelera o valor para os principais impulsionadores de negócios da empresa.
PCA
O PCA usa as mesmas vantagens de modelagem que o PLS do dataPARC oferece, permitindo fácil geração de modelos. A diferença entre os dois métodos de modelagem é que o PLS busca modelar e imitar uma única variável usando variáveis adjacentes como entradas do modelo. O PCA não modela uma única variável, mas modela um processo inteiro.
O valor vem ao comparar o processo atual com o processo modelado. O PCA dá ao usuário a capacidade de saber quando o processo atual está desligado (quando comparado ao processo modelado) e identifica a(s) variável(eis) do processo “ofensiva(s)”.
O PCA faz uso de dois parâmetros (disponíveis também para o modelo PLS): DMODX (erro do modelo) e HT2N (Hotelling T2 Normalizado – fora da norma). As variáveis de entrada do modelo PCA são todas classificadas e a equipe pode ver qual(is) variável(is) está(ão) causando o problema. O PCA pode ser usado como um sistema de alerta precoce para ajudar as operações a ver um problema antes que ele aconteça.
O PARCmodel é licenciado separadamente, mas incorporado ao PARCview e facilmente acessado no menu de tendência do botão direito. O PI não tem ferramentas de análise semelhantes.
Procurando substituir o ProcessBook Veja por que o PARCview é considerado a alternativa nº 1 ao ProcessBook.
Desenvolvimento e suporte centrados no cliente
Na dataPARC, acima de tudo está o cliente e suas necessidades práticas, oportunas e muito reais. A estratégia da dataPARC envolve uma alta atenção às necessidades do cliente e resolução rápida de problemas.
A dataPARC emprega muitas PMEs que atuam em funções-chave de suporte de engenharia de processos para empresas operacionais no setor. Ao longo dos anos, os recursos de usuário e a arquitetura geral do sistema do dataPARC foram moldados pelas PMEs e clientes. O dataPARC é construído por usuários finais para usuários finais.
Na dataPARC, vendemos mais do que software, vendemos nossos serviços para ajudar a criar tendências, gráficos e outras exibições para fazer seu sistema decolar. Nossos engenheiros e equipe de suporte estão disponíveis para ajudar a implementar novos projetos e oferecer suporte contínuo.
Com a PI, para criar as mesmas exibições, os clientes teriam que terceirizar para terceiros. A dataPARC é um balcão único.
Conclusão
A dataPARC e a PI têm muito em comum, no entanto, a dataPARC tem a vantagem onde importa – experiência do usuário, velocidade dos dados e custo. A dataPARC é simples, rápida e eficaz.
As vantagens da dataPARC em relação à PI continuam a crescer com cada novo recurso e atualização. Recursos que são impulsionados por usuários e clientes.
Baixe o guia
Descubra as principais alternativas aos kits de ferramentas de análise ProcessBook e PI Vision da PI.






