En las industrias de procesos, la optimización es la clave de la eficiencia. Y la eficiencia es lo que conduce a las ganancias, para que los fabricantes puedan producir más y desperdiciar menos. Para optimizar sus procesos, muchos fabricantes utilizan una combinación de historiador de datos de series de tiempo y software de visualización de datos. dataPARC y PI son dos de los líderes en este espacio; en este artículo compararemos dataPARC vs PI y destacaremos algunas de las ventajas que dataPARC tiene sobre PI como sistema de gestión de información de procesos.
Eche un vistazo a las herramientas de análisis de datos de procesos en tiempo real de dataPARC y vea cómo es que unos mejores datos pueden conducir a mejores decisiones.
dataPARC vs PI: Similitudes
dataPARC y PI existen desde hace décadas y tienen grandes bases de instalación representadas por los principales fabricantes de todo el mundo.
Tanto dataPARC como PI:
- Ofrecen un historiador de datos en tiempo real
- Utilizan un archivo binario, de índice en clúster y plano para almacenar el historial
- Tienen una estructura de activos para abordar las complejidades de las grandes fuentes de datos dispares
- Ofrecen muchas de las herramientas de análisis y visualización esperadas: tendencias, gráficos, informes
- Pueden conectarse a varios sistemas de control para recopilar datos de series temporales en tiempo real
- Utilizan una función de almacenamiento y reenvío en caso de que se pierda la conectividad de datos
- Pueden trabajar con sistemas de recuento de tags muy grandes
Ahora, profundicemos más en sus diferencias y veamos cómo es que dataPARC destaca.
dataPARC vs PI: Diferencias
Costo
También podríamos comenzar con lo que será una de las consideraciones clave al evaluar estos dos kits de herramientas de visualización de datos de proceso e historiador de datos.
En pocas palabras, el costo total de propiedad de dataPARC es menor en comparación con otras soluciones “similares” de la industria. Tanto el costo inicial como los costos continuos son considerablemente inferiores a los de PI System.
Usuarios ilimitados
Una razón clave para esto es el modelo de licencia ilimitada de dataPARC, que lo convierte en una excelente opción para las organizaciones que desean presentar los datos de producción a los responsables de la toma de decisiones en todos los niveles de la planta, sin tener que preocuparse por comprar licencias adicionales.
PI utiliza un modelo de precios por usuario. Esto tiende a funcionar para organizaciones pequeñas con solo unas pocas personas que necesitan acceder a la plataforma, pero para organizaciones más grandes o implementaciones empresariales, el costo se acumula rápidamente.
Con dataPARC, todos los que necesitan acceso a los datos pueden tener acceso sin costo adicional, lo que pone el poder de tomar decisiones de datos en manos de cada empleado.
¿Busca una alternativa al historiador de datos de PI? Obtenga un historiador de datos de planta empresarial a una fracción del costo. Eche un vistazo a PARCserver Historian de dataPARC.
Experiencia de usuario
Cuando se pregunta a los clientes sobre los 3 a 5 principales beneficios de dataPARC, la facilidad de uso siempre está en la parte superior de la lista. La complejidad reducida del sistema dataPARC permite que incluso el individuo menos “experto en computadoras” comience a crear contenido y a ganar valor, y da como resultado una amplia adopción de las herramientas dentro de una organización.
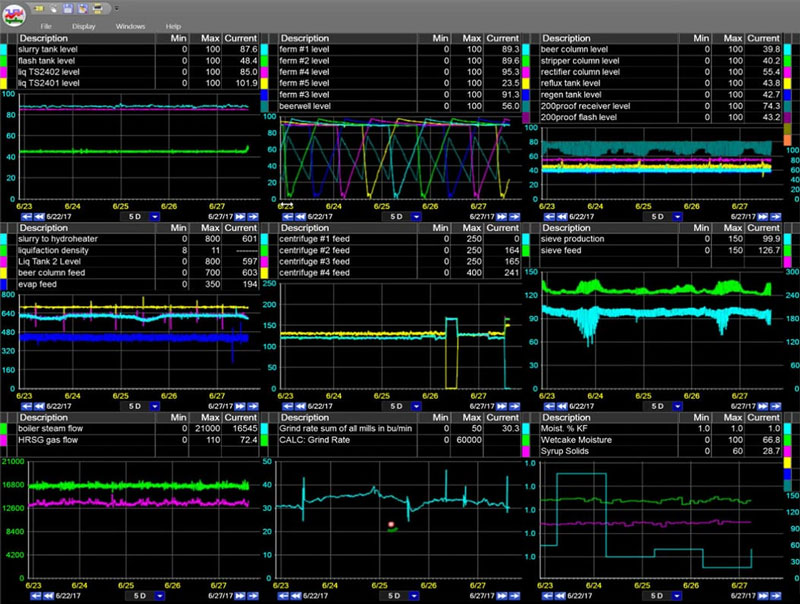
Aunque hay muchas funciones para dataPARC, un nuevo usuario puede aprender a buscar tags, tendencias y navegar en cuestión de minutos. A partir de ahí, los usuarios aprenden rápidamente que pueden ver estadísticas de tendencias, administrar eventos de alarma, exportar datos, crear pantallas como gráfico X/Y, histograma o Pareto y mucho más, todo desde el menú de clic derecho.
Las herramientas de tendencias de dataPARC han sido reconocidas durante mucho tiempo por los clientes como la solución de tendencias número 1 en la industria. Las capacidades de tendencias de dataPARC son más rápidas y superiores a las demás, y encajan mejor en el ámbito de las funciones prácticas.
Ningún otro paquete permite una construcción más rápida de una matriz de tendencias, con un rápido proceso de arrastrar y soltar tanto desde el explorador de tags como desde las pantallas.
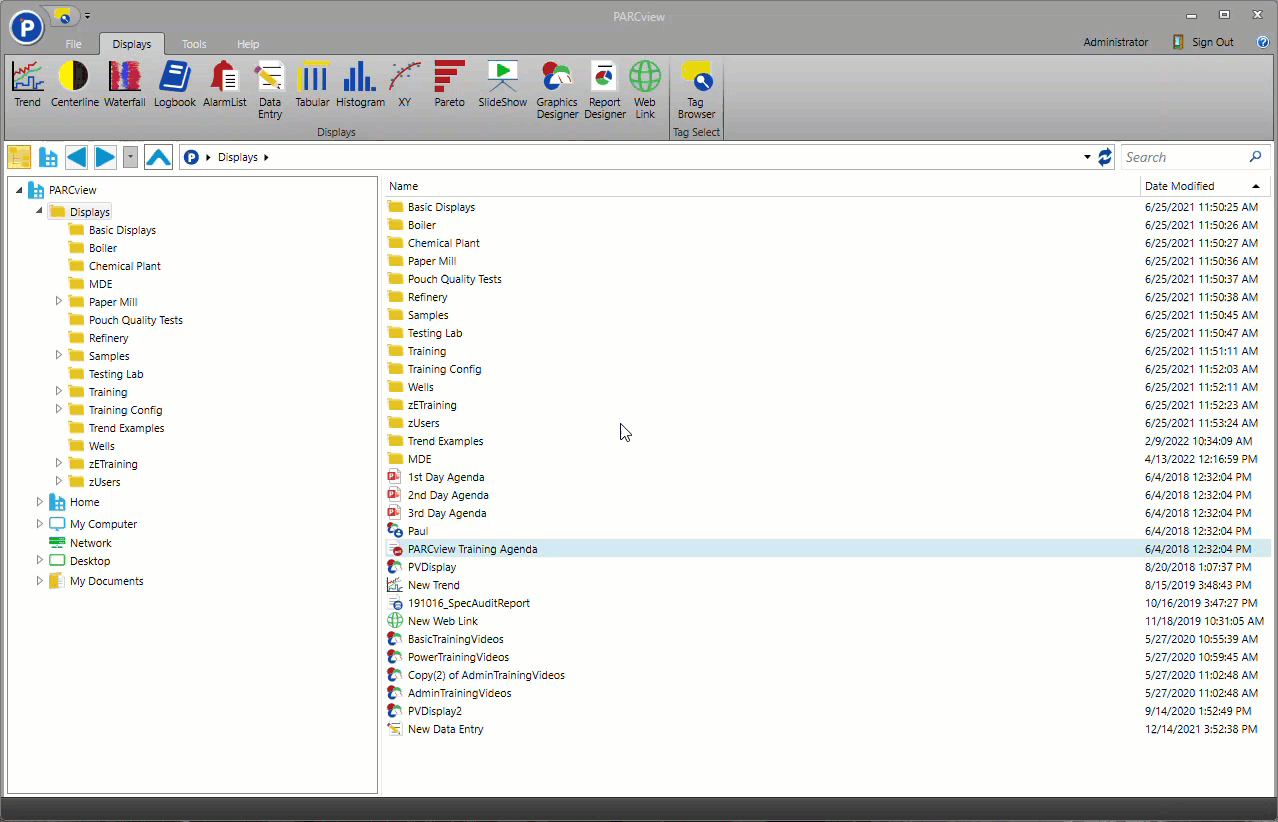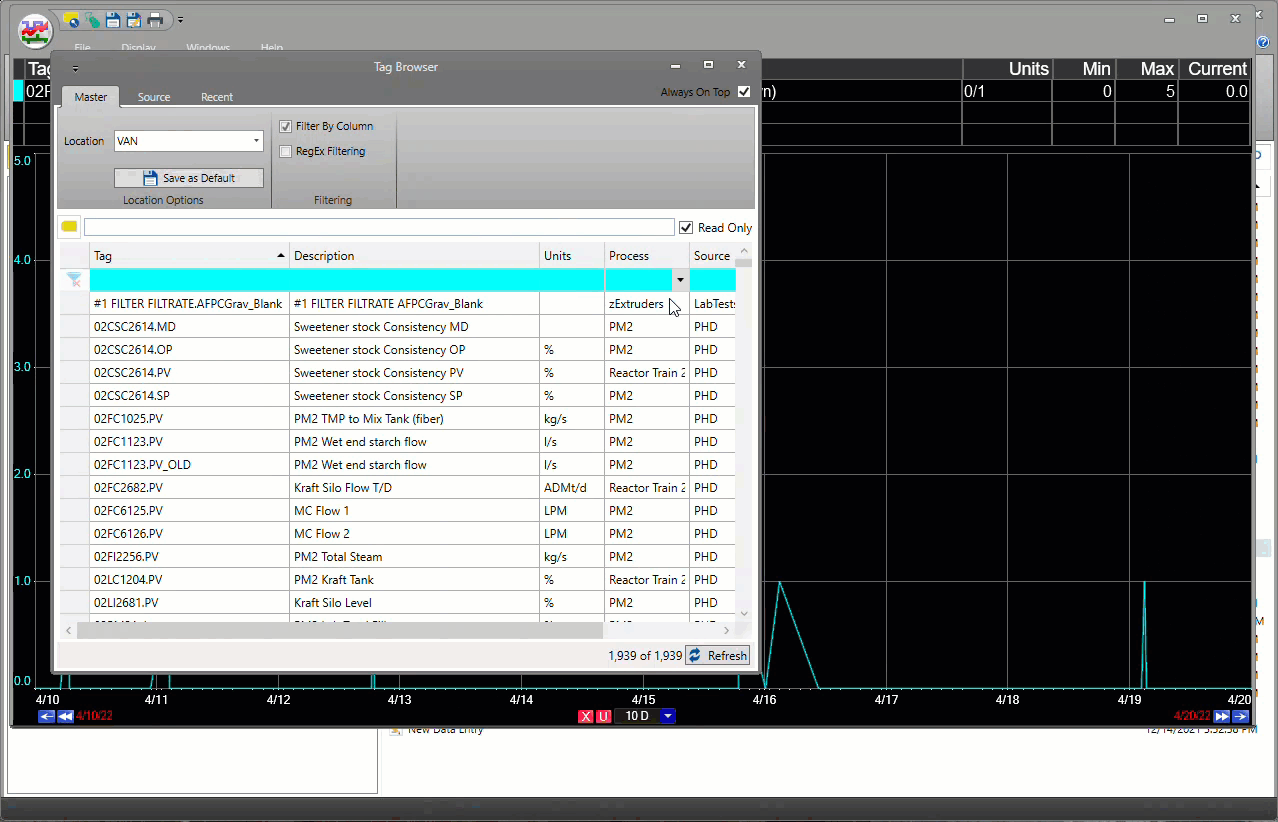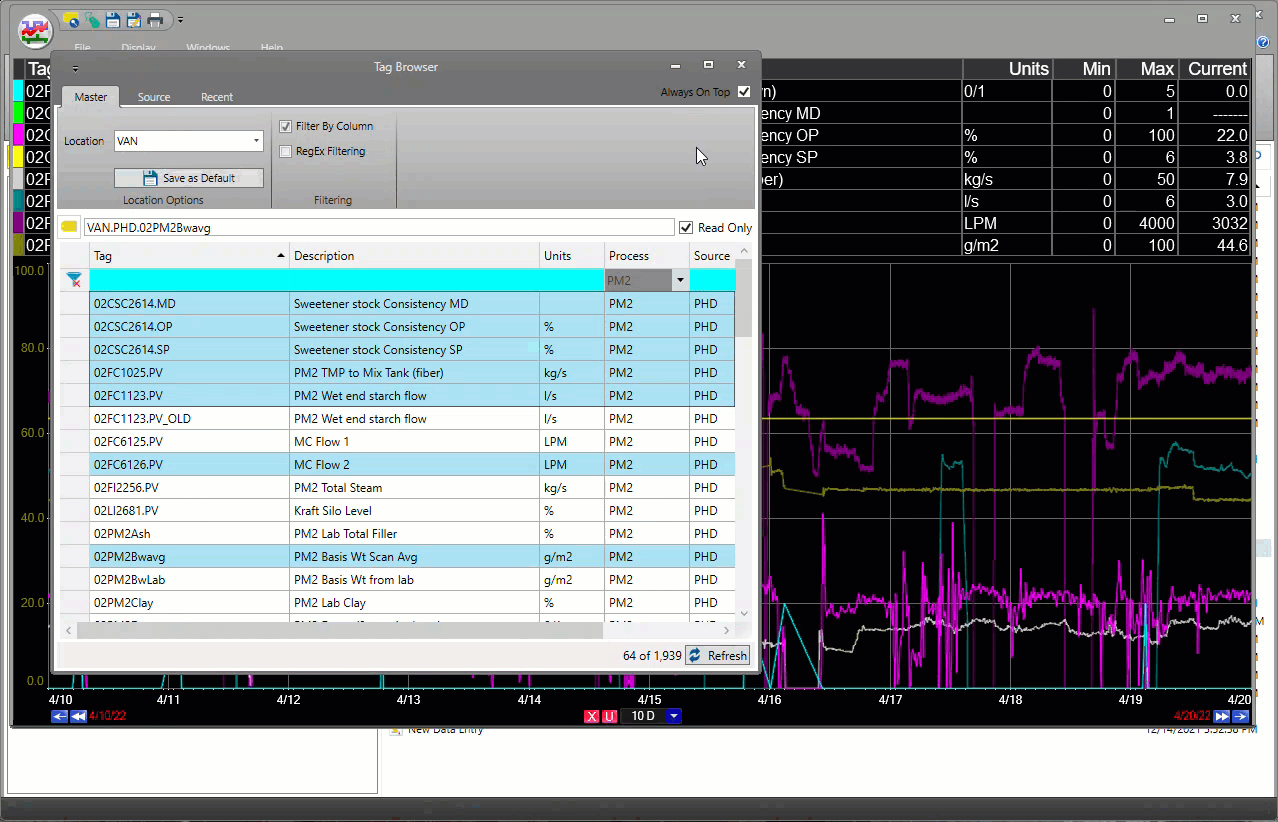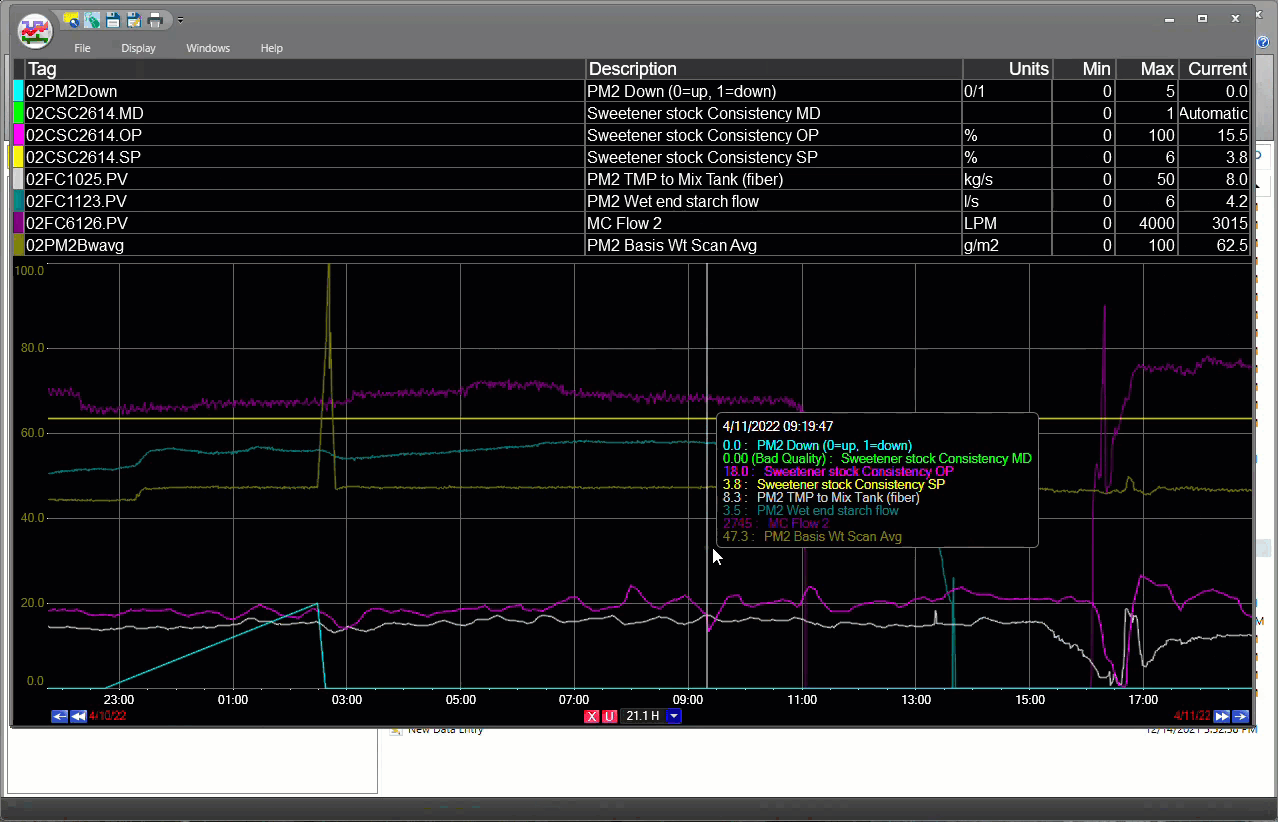
dataPARC hace que encontrar y generar tendencias de datos de tags sea muy fácil.
Desde entonces, muchas organizaciones que se establecieron con PI Historian y ProcessBook han optado por hacer que dataPARC se “asiente sobre” su PI Historian simplemente para PARCview; las herramientas de visualización y la facilidad de uso hablan por sí mismas.
Análisis de diagnóstico
Como se mencionó anteriormente, la aplicación de tendencias de dataPARC se considera la mejor de la industria. No solo por su facilidad de uso y rápido acceso a las herramientas de análisis, sino también por su velocidad.
Tendencia
dataPARC utiliza una estrategia deliberada de velocidad de datos con múltiples componentes, incluido un motor de datos de rendimiento (PARCpde) integrado para acelerar los datos al usuario. El objetivo es cumplir y superar la “velocidad de pensamiento” del usuario. PARCpde es una parte fundamental de todo el sistema dataPARC.
Las pruebas de velocidad que comparan dataPARC vs. PI y otros historiadores contemporáneos han demostrado que dataPARC es entre 10 a 50 veces más rápido en la entrega de conjuntos de datos grandes o a largo plazo al usuario.
Varias empresas han cambiado a dataPARC en parte debido a la velocidad de los datos. dataPARC también utiliza un archivo agregado y un archivo acumulativo en su arquitectura, lo que reduce en gran medida la cantidad de tiempo perdido al resolver problemas o investigar oportunidades.
A partir de la tendencia, los usuarios pueden lanzar una cuadrícula de estadísticas rápidas, generar un nuevo trazo X/Y o mostrar un histograma. Cada gráfico extraerá los tags de la tendencia, por lo que los usuarios no tendrán que volver a buscarlos en el Explorador de Tags.
El gráfico X/Y establece dos tags para la comparación y se puede generar una línea de mejor ajuste: lineal, polinómica, etc. La fórmula generada a partir del ajuste se puede mostrar en una tendencia u otra pantalla. PI también puede generar gráficos X/Y, pero se crean desde cero y no se genera ninguna línea de mejor ajuste.
Complemento de Excel
El Complemento de Excel de dataPARC se creó con un alto grado de facilidad de uso y velocidad.
PI’s PI DataLink y dataPARC tienen funciones dentro de la celda que pueden extraer datos directamente en Excel. El complemento de dataPARC tiene varias otras funciones.
Hay una hoja que puede extraer tags múltiples en el mismo rango de tiempo sin tener que lidiar con fórmulas. Los usuarios pueden importar listas de tags de pantallas de dataPARC ya creadas en lugar de volver a buscar los tags.
Además del valor obtenido en las herramientas de complementos de Excel heredadas, dataPARC se destaca por lo siguiente:
- Arrastrar grupos de tags/datos a Excel desde múltiples fuentes de datos
- Filtrar datos en función de múltiples valores de tags
- Correlación cruzada/generación de matriz R2
- Gráficos CUSUM y MSR
Además, los usuarios pueden mostrar datos basados en series de tiempo de Excel en las tendencias y pantallas de PARCview. Esto se puede utilizar para establecer tendencias o comparar datos externos a la empresa justo al lado de los datos de proceso.

Evalúe las principales alternativas a ProcessBook y PI Vision en nuestra PI Server Data Visualization Tools Buyer’s Guide.
Gestión de operaciones
La gestión de operaciones en tiempo real es necesaria para mantener una planta funcionando con la máxima eficiencia y para poder responder rápidamente a las excursiones del proceso que resultan en tiempo de inactividad no planificado o pérdida de producto.
dataPARC facilita esto de varias maneras:
- Pantallas gráficas del proceso
- Dashboards de datos de KPI y laboratorio
- Herramientas de entrada manual de datos (MDE)
- Informes automatizados
- Alarmas y notificaciones de procesos
- Y más
Al comparar dataPARC vs PI, ambos ofrecen la creación de dashboards gráficos dinámicos y llenos de información, pero solo dataPARC tiene la pantalla de Centerline.
Centerline
Centerline es una poderosa herramienta de monitoreo exclusiva de dataPARC. Es una pantalla en tiempo real que informa estadísticas basadas en tags. Las ejecuciones pueden basarse en el grado o el tiempo, y las estadísticas incluyen la media de tiempo, la desviación estándar, CpK, mín, máx, etc.
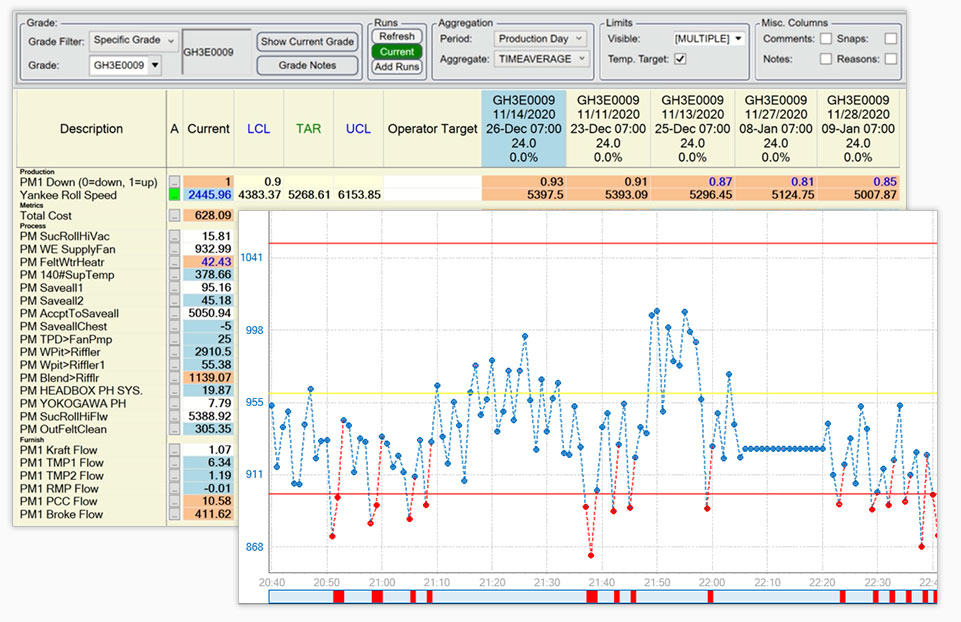
Centerline muestra datos para períodos de tiempo o series con el fin de garantizar que las condiciones del proceso sean las mismas una serie tras otra.
El propósito de una pantalla de Centerline es ayudar a determinar las mejores configuraciones operativas para la producción y garantizar que esas configuraciones se utilicen normalmente durante la producción.
Centerline es una de las potentes herramientas de análisis de datos de dataPARC para la que no existe un equivalente de PI.
Alarmas y notificaciones
El sistema de alarmas y notificaciones de dataPARC puede enviar correos electrónicos, notificaciones de texto o activar flujos de trabajo cuando se detecta o cierra una alarma. Una vez que se detecta una alarma, se crea un evento de alarma. Estos eventos se pueden ver y reconocer en una lista de tendencias, líneas centrales, gráficos o alarmas. Los usuarios pueden reconocer el evento al asignar un motivo desde el árbol de motivos y/o escribir un comentario en el evento. Se puede realizar un análisis rápido en dataPARC con el diagrama de Pareto para determinar las principales razones guardadas para una alarma, o crear un informe tabular ordenado por razones con todos los comentarios visibles.
Del mismo modo, las notificaciones PI pueden crear marcos de eventos y enviar notificaciones. Una vez que se detectan los marcos de eventos y se asigna un motivo, los usuarios pueden ver estos datos como una tabla en PI Vision, pero es necesario realizar más análisis o informes en el PI Excel Add-In DataLink. El dataPARC Excel Add-In también tiene funcionalidades para extraer datos de los eventos de alarma.
En la siguiente sección se exploran más funciones del dataPARC Excel Add-In.
Entrada manual de datos (MDE)
La pantalla MDE de dataPARC se configura rápidamente y permite a los usuarios introducir y guardar datos manuales en la base de datos, en lugar de hacerlo en una hoja de papel o en Excel.
Los datos introducidos manualmente se representan mediante tags, por lo que se pueden utilizar en las tendencias, dashboards y pantallas de PARCview como cualquier otro tag.
¿Necesita poner mejores datos en manos de sus ingenieros de procesos? Eche un vistazo a nuestras herramientas de análisis de procesos en tiempo real y vea cómo unos mejores datos pueden conducir a mejores decisiones.
Cálculos
Cuando los usuarios no tienen el tag perfecto para ayudar a administrar un proceso, a menudo se usa un tag del calc o MDE. dataPARC y PI pueden realizar cálculos simples como agregar tags, enunciados If/Then o conversiones de unidades.
Con PI Vision, PI Analytics ya no es compatible con scripts VB. Las secuencias de comandos de VB abren las puertas a soluciones personalizadas y dataPARC aprovecha las secuencias de comandos de VB para aplicaciones como lecturas de bases de datos, análisis de archivos, llamadas a servicios web y mucho más.
Modelado de activos
Tanto Asset Hub de dataPARC como Asset Framework (AF) de PI ofrecen formas de estructurar y contextualizar datos de series temporales mediante la organización de etiquetas en torno a activos físicos. Aunque PI AF es potente, a menudo requiere una configuración más compleja mediante herramientas y scripts externos. Por el contrario, Asset Hub está diseñado específicamente para ingenieros y operadores, y ofrece una interfaz más intuitiva de apuntar y hacer clic para crear y gestionar jerarquías de activos sin necesidad de formación especializada.
Lo que distingue a Asset Hub es su estrecha integración con las herramientas de tendencias, paneles de control y alarmas de dataPARC. Los usuarios pueden navegar rápidamente desde la vista general de la planta hasta los activos individuales y ver los KPI en tiempo real, las tendencias históricas y los límites de rendimiento en un solo lugar.
Acceso web y flexibilidad
En lo que respecta al acceso web, los usuarios del sistema PI están limitados a PI Vision, una herramienta totalmente basada en la web. Aunque proporciona una forma centralizada de ver los datos, carece de una contraparte de escritorio, lo que puede ser una limitación para los usuarios que prefieren o necesitan una aplicación más robusta e instalada localmente. Algunas de las deficiencias se han expresado en las secciones anteriores, incluyendo los cálculos.
dataPARC ofrece tanto una aplicación de escritorio con todas las funciones (PARCview) como una versión basada en navegador. Este enfoque híbrido ofrece a los equipos la flexibilidad de elegir la mejor herramienta para la tarea, ya sea en la sala de control, en un ordenador portátil o trabajando a distancia.
Análisis predictivo
PARCmodel de dataPARC ofrece un grado de análisis predictivo con capacidades de modelado PLS (Mínimo cuadrado parcial) y PLC (Análisis de componentes principales).
PLS
El paquete PLS ha sido descrito por uno de los mejores ingenieros de modelado práctico del mundo como “… sin excepción, mejor que cualquier cosa que haya visto antes”. En la industria de procesamiento, una de las aplicaciones para el modelado PLS es la construcción de predictores de propiedades inferenciales (IPP).
Los ingenieros de control en empresas operativas informan que la generación de un modelo PLS para un IPP puede tardar más de 8 horas en remodelarse (más tiempo para el modelo inicial) utilizando múltiples herramientas y actividad fuera de línea. dataPARC lo integra todo en una sola herramienta y el esfuerzo de remodelación puede ser de tan solo 5 minutos.
Esta rápida generación de modelos permite generar múltiples soluciones para comparar y encontrar la mejor opción. La velocidad de remodelación permite una aplicación más amplia y el beneficio de PLS. Los métodos prácticos de ingeniería e incluso las “corazonadas” de procesos ahora pueden respaldarse con una validación rápida mediante una sesión matemática de PLS en un periodo de 2 a 5 minutos.
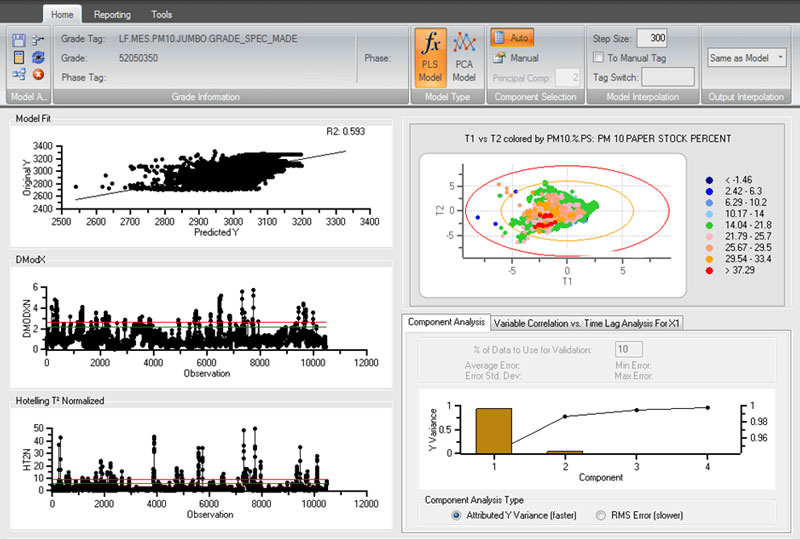
Herramientas de modelado predictivo de dataPARC
dataPARC ofrece un gran ahorro de tiempo, un mejor entorno de aprendizaje, un mejor entorno de colaboración y aplicaciones más útiles; todo esto acelera el valor para los principales impulsores comerciales de la empresa.
PCA
PCA utiliza las mismas ventajas de modelado que ofrece PLS de dataPARC, lo que permite una fácil generación de modelos. La diferencia entre los dos métodos de modelado es que PLS busca modelar e imitar una sola variable mediante el uso de variables adyacentes como entradas de modelo. PCA no modela una sola variable, sino que modela todo un proceso.
El valor viene al comparar el proceso actual con el proceso modelado. PCA le da al usuario la capacidad de saber cuándo está apagado el proceso actual (en comparación con el proceso modelado) e identifica la(s) variable(s) de proceso “infractora(s)”.
PCA hace uso de dos parámetros (disponibles también para el modelo PLS): DMODX (error del modelo) y HT2N (Hotelling T2 Normalizada – fuera de norma). Las variables de entrada del modelo PCA se califican y el personal puede ver qué variable(s) está(n) causando el problema. PCA se puede utilizar como un sistema de alerta temprana para ayudar a las operaciones a ver un problema antes de que suceda.
PARCmodel tiene licencia por separado, pero se incorpora a PARCview y se utiliza fácilmente en el menú de tendencia con el botón derecho del ratón. PI no tiene herramientas de análisis similares.
Si busca reemplazar ProcessBook Vea por qué PARCview se considera la alternativa #1 de ProcessBook.
Desarrollo y asistencia centrados en el cliente
En dataPARC, por encima de todo está el cliente y sus necesidades muy reales, oportunas y prácticas. La estrategia de dataPARC implica una alta atención a las necesidades del cliente y la resolución rápida de problemas.
dataPARC emplea a muchos SME (expertos en la materia) que desempeñan funciones clave de soporte de ingeniería de procesos para empresas operativas en la industria. A lo largo de los años, las características de usuario y la arquitectura general del sistema de dataPARC han sido moldeadas por los SME (expertos en la materia) y los clientes. dataPARC es construido por los usuarios finales para los usuarios finales.
En dataPARC vendemos más que software; vendemos nuestros servicios para ayudar a crear tendencias, gráficos y otras pantallas para que su sistema comience a funcionar. Nuestros ingenieros y personal de soporte están disponibles para ayudar a implementar nuevos proyectos y ofrecer soporte continuo.
Con PI, para crear las mismas pantallas, los clientes tendrían que subcontratar a un tercero. dataPARC es una solución centralizada.
Conclusión
dataPARC y PI tienen mucho en común; sin embargo dataPARC tiene la ventaja donde importa: la experiencia del usuario, la velocidad de los datos y el costo. dataPARC es simple, rápido y efectivo.
Las ventajas de dataPARC frente a PI continúan creciendo con cada nueva función y actualización. Funciones impulsadas por usuarios y clientes.
Descargar la guía
Descubra las principales alternativas a los kits de herramientas de análisis ProcessBook y PI Vision de PI.







