製造業はAIへの投資を加速させていますが、多くの企業が直面する課題は共通しています。AIが真の価値を発揮するには、基盤となるデータインフラが整備されている必要があるのです。そこでAI実現基盤の重要性が高まります。既存システムを置き換えたり、全面的なデジタル刷新を強いるのではなく、AI実現基盤は工場現場のデータ、実験室の結果、企業システムを、分析ツールや機械学習ツールが実際に活用できる形で統合する「結合組織」を提供する。
本ブログでは、dataPARCが製造業向け強力なAI実現基盤として機能し、チームがデータを統合し、モデルを迅速に構築・展開し、意思決定が行われる現場のオペレーターにリアルタイムのAIインサイトを届ける方法を解説する。
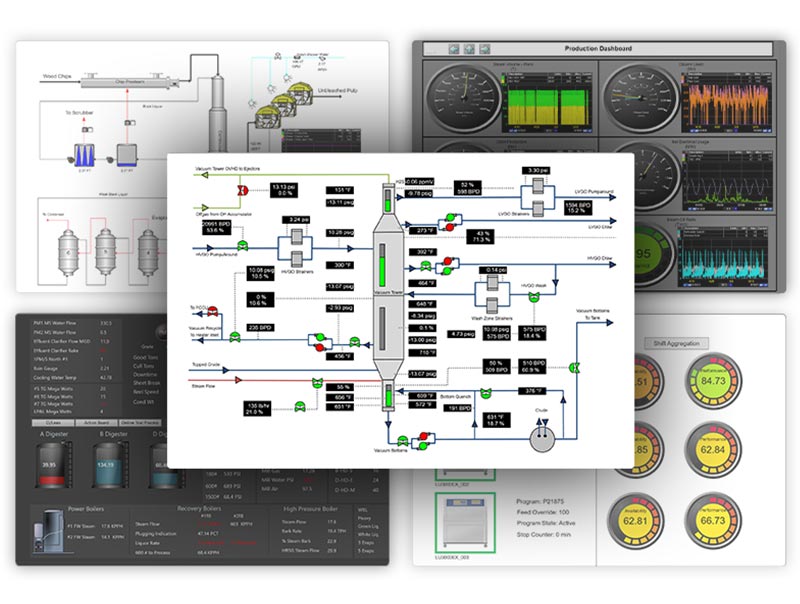
高速データヒストリアンとプロセス監視で製造エコシステムを整備
製造業がAI活用基盤を必要とする理由
AIと機械学習は、品質予測からエネルギー最適化まで、製造のあらゆる分野に浸透しつつある。しかし、これらのモデルが価値を発揮するには、工場が適切なデータを供給し、その結果をオペレーターが迅速に判断できる速度でフィードバックする必要がある。AIシステムには、アクセス可能で部門横断的に連携され、生産ロット、実験室データ、オペレーター注記、イベントなどの豊富な文脈情報を含むデータが求められる。
大半の工場では、デフォルトでそのような運用は行われていない。プロセスデータは一つのシステムに、実験室データは別のシステムに、保守データはさらに別のシステムに、そして基幹システムは独自の孤立した環境に存在する。これら全てのデータソースが存在する場合でも、同じ言語で通信したり、同じ構造を共有したりすることは稀だ。このギャップにより、モデル構築や導入自体が困難になるだけでなく、実際の運用で結果を信頼することも難しくなる。
これが製造業にAI実現基盤が必要な理由だ。OTとITの架け橋として機能し、プロセス信号・検査結果・稼働データ・イベントを統合し、分析可能な環境を構築する。チームにカスタム連携やインフラ刷新を強いる代わりに、基盤層がモデルに必要な接続性と文脈を提供し、AI出力をオペレーターやエンジニアにリアルタイムで還元する。
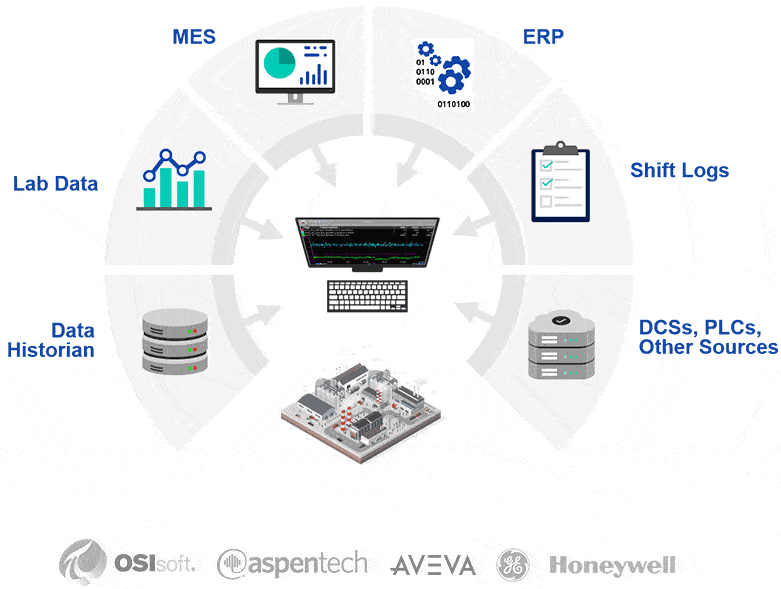
PARCviewは全システムのデータを一元収集し、整合性を保った状態でサードパーティ製AIシステムへ送って高度な分析を実行可能にします。
要するに、AIは生データだけでは機能しません。データが組織化され、文脈化され、プラント全体でアクセス可能になった時に初めて成功するのです。AI実現基盤はこれを可能にし、日常業務を妨げずに高度な分析を適用するための実用的で拡張性のある基盤を製造業者に提供します。
データPARCが運用とAI/機械学習を接続する方法
工場内でAIを活用するには、運用システムとモデルを訓練・検証・実行する分析ツール間でデータが円滑に移動する必要があります。データPARCは、リアルタイム運用と最新のAI/MLプラットフォームを橋渡しする統合データ環境を構築することで、この接続点を提供します。
基盤となるのは統合された接続性です。dataPARCはOPC、SQL、REST、クラウドインターフェースを通じてプロセス、ラボ、メンテナンス、エンタープライズデータを統合し、従来OTシステムとITシステムを隔てていたサイロを解消します。これによりエンジニアとデータサイエンティストは、カスタムコネクタや手動ワークフローを構築することなく、同一の一貫したデータセットから作業できます。
次にdataPARCはコンテキスト化を適用し、生のタグデータを生産ロット、実験室結果、オペレータコメント、イベント履歴と関連付けます。これにより、正確な特徴量エンジニアリング、トレーニング用データ選択、長期的なモデル性能に不可欠な、構造化され分析準備が整ったモデルが生成されます。AIツールは断片化または曖昧なデータストリームではなく、クリーンで一貫性のある入力を受け取ります。
モデル構築後、dataPARCはワークフローを通じて閉ループを実現します。モデルの予測値、信頼度スコア、推奨設定値は、オペレーターやエンジニアが既にプロセスを監視しているPARCviewダッシュボードに直接配信されます。これによりリアルタイムの意思決定支援が可能となり、AIの知見が他システムやオフラインレポートに閉じ込められることを防ぎます。
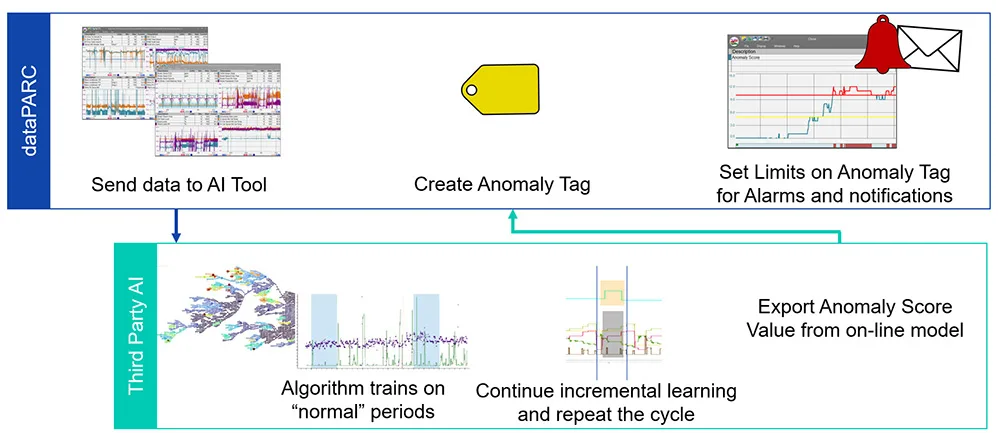
これは、dataPARCとサードパーティ製AIの連携手順を示しています。生データがAIソフトウェアに送信され、高値でアラームをトリガーさせるタグとしてdataPARCに再挿入されます。
バックエンドでは、dataPARCのシームレスな統合により、データが双方向で確実に流れることが保証されています。プラント現場からクラウドへのモデル開発用データ、そしてモデルから日常運用へのデータが双方向に流れます。
その結果、AIが独立した分析作業ではなく、日常的なプラントワークフローの一部となる、実用的な生産対応環境が実現します。
AIインサイトをオペレーターへリアルタイムで還元
AI対応システムを構築するには、基盤となるデータが完全かつ文脈化され、システム間で整合されていることが必須です。dataPARCは、モデリング・分析・リアルタイム推論に備え、プラントの生データをAI対応インテリジェンスへ変換します。
本プラットフォームは、OT/ITシステム全体、プロセスタグ、実験室データ、生産ロット、ダウンタイム事象、オペレーターコメントから情報を集約し、統一モデルとして構造化します。これにより、モデル開発を遅延させる不整合なフォーマット、命名規則の差異、タイミングのずれを解消。プロセス領域別に整理されたデータが情報の文脈化を支援します。
モデルが展開可能になると、dataPARCは必要な信号をプラント環境にフィードバックし、リアルタイム推論を実現します。フォルダやファイルへエクスポート可能なモデル出力は、PARCviewタグへ自動インポートされます。これによりユーザーは値のトレンド分析、アラーム設定、ダッシュボード表示が可能となり、意思決定の瞬間にAIインサイトがオペレーター・エンジニア・監督者に確実に伝達されます。
断片化したデータを構造化された運用インテリジェンスへ変換することで、dataPARCは産業用AI導入の最大の障壁の一つ——情報の大規模な活用性・一貫性・実用性——を解消します。
今日から導入可能な実用的なAIユースケース
dataPARCが提供する統合接続性、コンテキスト化、リアルタイム可視化により、製造業者は既存システムを置き換えることなく、意味のあるAIアプリケーションを導入できます。日常的に活用できるユースケースの例をいくつかご紹介します:
予知保全
- 異常検知や故障予測モデルを用いて、設備の劣化を早期に検出。
- PARCviewに表面予測スコアを直接挿入し、保守計画の指針とする。
品質予測と最適化
- 機械学習品質モデルを稼働中の生産環境に接続。
- オペレーターに規格外リスクのリアルタイム予測と推奨調整値を提供。
エネルギー・ユーティリティ最適化
- AIで蒸気・電力・水・圧縮空気使用の非効率性を可視化。
- 最適化推奨値をオペレーターにフィードバックし即時対応を促進。
プロセス最適化
- 設定値調整を推奨するモデルやプロセスドリフトを検知するモデルで継続的改善を支援。
- PARCviewで予測性能と実性能を並列比較。
需要予測と計画
- 予測モデルを生産ダッシュボードと統合。
- 予測需要・価格・供給制約に連動した運用を実現。
これらのアプリケーションに共通する要件:アクセス可能で一貫性のある文脈化データ。この基盤を提供し、日常業務に知見を還元することで、dataPARCは製造業者が探索的AIプロジェクトから実際の運用成果へ移行するのを支援します。

AI対応データエコシステムの実態が気になる方へ。この動画で解説します
製造業者がAI導入にdataPARCを選ぶ理由
dataPARCが際立つ理由は、実際の産業環境においてAIを実用的かつ利用可能でスケーラブルにする点にあります。チームを硬直的なアーキテクチャやデータサイエンス専用のワークフローに縛るのではなく、オペレーター、エンジニア、アナリストが同じ信頼できるデータ基盤から作業できるように支援します。製造業者がdataPARCを選ぶ理由は、以下の価値を提供するためです:
運用向けに設計された使いやすさ
エンジニアとオペレーター向けに設計されたdataPARCは、可視化、トラブルシューティング、意思決定支援のための直感的なツールを提供します。AIインサイトは既存のワークフローに統合され、孤立した分析プロジェクトとはなりません。
拡張性と信頼性を兼ね備えた基盤
単一プラントから複数拠点のエンタープライズ展開まで、dataPARCは高解像度データ、長期保存、ハイブリッドアーキテクチャを確実に処理します。パフォーマンスや制御性を損なうことなく、オンプレミス、クラウド、混合環境をサポートします。
統合されたOT-IT接続性
dataPARCはSCADA、DCS、実験室システム、MES、ERP、クラウド分析プラットフォームを単一環境に統合します。この統一ビューにより、AIモデルは必要な完全な運用コンテキストにアクセスできます。
AI/MLツールとのシームレスな統合
Azure、Databricks、Python、Snowflake、あるいは内部のデータサイエンスパイプラインのいずれを使用する場合でも、dataPARCはトレーニングと推論のためのクリーンで文脈化されたデータを提供します。モデル出力はPARCviewにフィードバックされ、リアルタイムでの運用化を実現します。
業界を横断した実証済みの信頼性
dataPARCは、パルプ・製紙、化学、精製、発電、食品・飲料など、幅広い業界で信頼されています。プラントは稼働時間、データ整合性、既存システムを再構築せずにAI取り組みを拡張する能力のためにこれを頼りにしています。
AI導入への実践的な道筋
全面的なデジタル刷新を要求する代わりに、dataPARCはチームの現状に即して対応します。現行の運用と高度な分析を橋渡しし、AI導入を段階的で達成可能かつ日常的な生産ニーズに沿ったものにします。
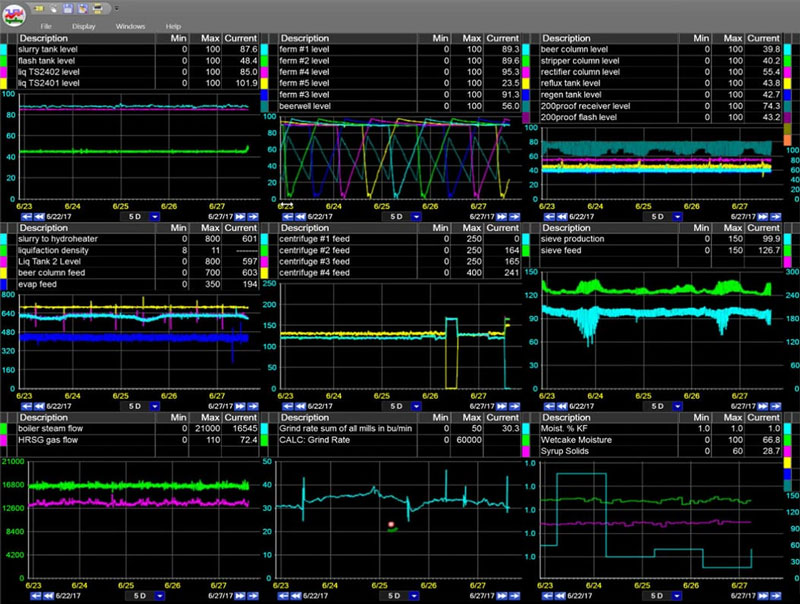
データPARCのリアルタイムプロセスデータ分析ツールを確認し、優れたデータが意思決定をいかに向上させるかをご覧ください。
FAQ: 製造業向けAI実現基盤としてのdataPARC
- 製造分野における「AI実現基盤」とは何を意味しますか?
AI実現基盤とは、AIと機械学習が効果的に機能するために必要な基盤データインフラを提供します。これにはOTデータとITデータの連携、信号の文脈化、高解像度履歴の保存、分析ツール向けクリーンでアクセス可能なデータセットの提供が含まれます。dataPARCはプロセスデータ・ラボデータ・企業データを統合し、稼働中の業務を妨げずにAI対応可能な状態にします。 - dataPARCでAIを活用するには既存システムを置き換える必要があるか?
必ずしもそうではありません。dataPARCにはヒストリアン機能があり、統合・可視化レイヤーであるPARCviewは既存のヒストリアン、DCS/PLCネットワーク、ラボシステム、企業データベースと並列に動作します。置き換えではなく統合レイヤーとして機能するため、製造業者は現在のインフラを基盤にAIを段階的に導入しつつ、自社のペースでデータ環境を近代化できます。 - 現在dataPARCが対応可能なAIユースケースの種類は?
dataPARCは予測保全、品質予測、プロセス最適化、排出監視、エネルギーバランス調整、需要予測など、幅広いAI駆動型アプリケーションで活用されています。文脈化されたデータにより、これらのユースケースを日常業務に直接統合可能です。 - オペレーターやエンジニアはPARCview内でAIインサイトを実際に活用できますか?
はい。モデル予測、推奨設定、異常スコア、品質推定値をPARCviewダッシュボードに直接表示可能です。これによりオペレーターはリアルタイムのトレンドや設備データと連動したAIガイダンスを確認でき、迅速かつ確信を持った意思決定を実現します。 - AI導入拡大に伴い、dataPARCはどのように拡張しますか?
本プラットフォームは長期的な拡張性を考慮して構築されており、単一施設での導入から企業全体システムまであらゆる規模に対応します。タグ数の増加、データ量の拡大、追加のモデリングワークロードを、パフォーマンスを損なうことなく管理します。AIアプリケーションが増えるほど、dataPARCは全てを連携させアクセス可能にする中核データ基盤として機能します。
スマートファクトリーの構築
データ駆動型工場を実現するための製造業向けテクノロジー・ソフトウェアガイド

Digital Transformation Roadmap
Download our Digital Transformation Roadmap and learn what steps you can take to achieve data-driven success in manufacturing.








