在本篇博客中,我们将探讨历史数据记录系统与SCADA系统的差异,并阐明为何讨论重点不应是二者择一。相反,我们将剖析这些技术如何协同构建全面的运营数据生态系统,赋能团队实时监控流程并分析历史数据以实现长期改进。
高速、可扩展的数据历史库,成本仅为传统方案的零头。立即了解dataPARC Historian
从控制到洞察的转变
传统SCADA系统主要服务于监督控制与实时监控。它整合来自PLC、RTU和DCS系统的过程数据,可视化关键变量,使操作员能维持稳定的生产状态。SCADA在警报响应、设定值变更和联锁控制方面表现卓越,确保设备层面的安全可靠性。
随着制造业向数据驱动型运营转型,工厂信息系统的期望值不断提升。工程师不仅需要掌握当下状况,更需理解事件发生的原因与机制,并预测未来趋势。这要求具备高分辨率、长期过程数据,通过跨班次、批次或生产周期的分析,发掘短期SCADA数据无法揭示的规律与关联性。
SCADA系统的数据保留周期通常仅为数小时至数天。许多传统系统会在48-72小时后覆盖数据,或降采样为1分钟平均值,导致识别瞬态扰动或振荡行为所需的高频信号细节丢失。这种有限的数据历史无法满足高级分析、根本原因调查或依赖连续完整时间序列数据的机器学习模型需求。此外,数据仅限控制室内的少数客户端访问。这进一步限制了数据分析能力及自主数据利用权限。
数据历史库(如dataPARC Historian)正是为填补此缺口而设计。它以全分辨率持续采集时间序列数据,并采用高效存储方案实现无限期保存,完整保留数据上下文与粒度。这使工程师能够追踪多年工艺行为趋势,关联生产数据与质量指标,并分析能耗或吞吐效率的时序变化。
通过将关注点从实时控制延伸至长期洞察,历史数据系统将数据从运营必需品转化为战略资产,成为持续改进、预测性分析和智能制造决策的基础。
时间序列历史数据系统的独特价值
SCADA系统侧重实时监控与控制,而过程历史数据系统则专为长期数据采集、高频存储和高级分析而设计。差异不仅体现在数据保留能力上,更涉及数据完整性、可访问性及上下文关联性。
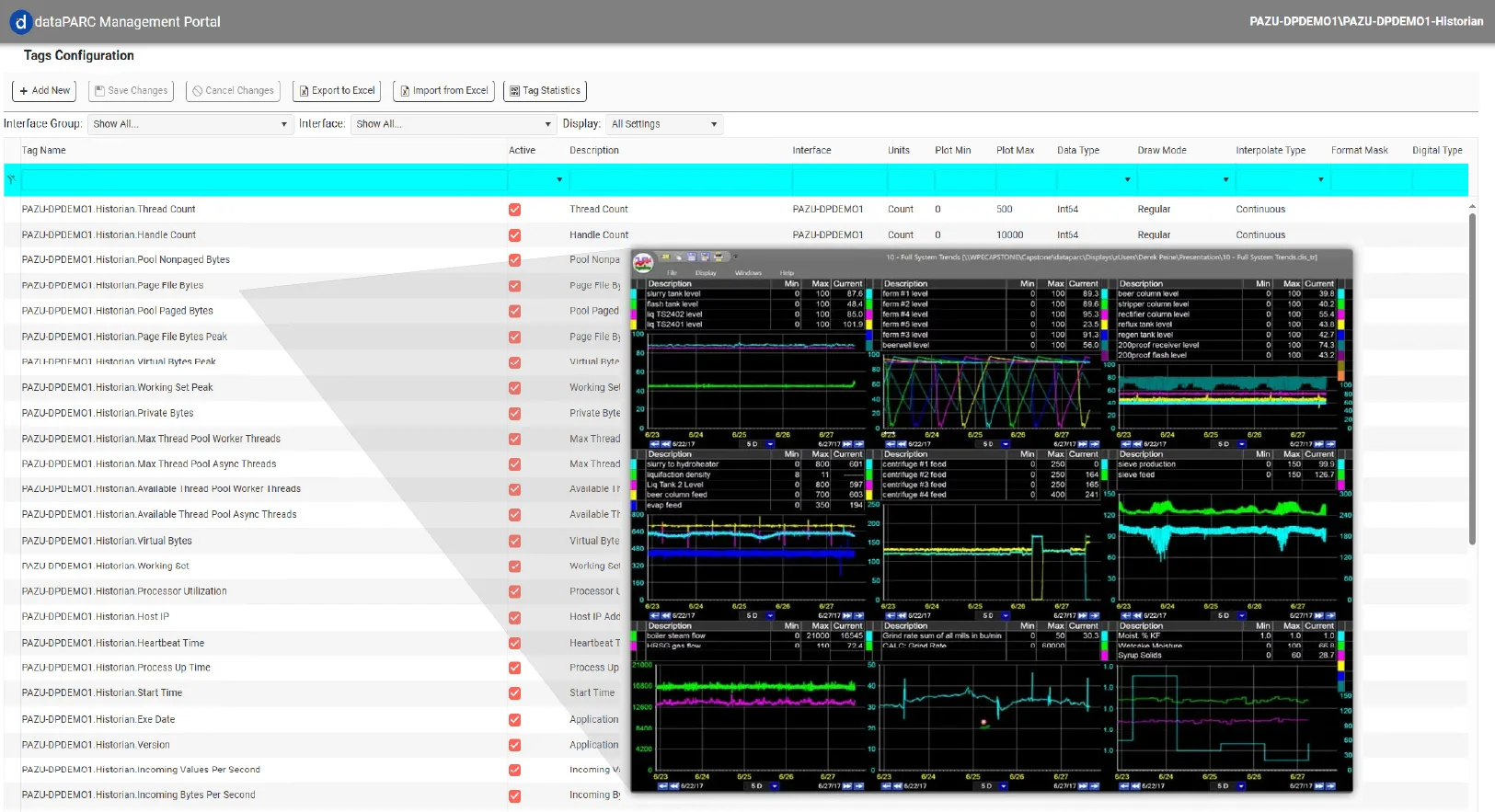
历史数据库能捕获并保存来自多系统数百乃至数千个过程标签的高精度时间序列数据。它采用持续追加方式存储数据,既保留原始数据集也维护聚合数据集,避免降采样或覆盖旧值。这种方法使工程师能够在不损失细节的前提下,分析任意时间点的工作状态。
SCADA系统侧重操作控制与报警功能,而历史数据库则记录每项趋势、事件和决策背后的完整时间序列数据,为深度分析和性能优化提供支撑。
不同于面向操作人员的SCADA系统,历史数据库服务于工厂多类角色:工艺工程师通过趋势分析比较不同批次或产品等级的运行状态;可靠性团队关联停机数据与振动/温度曲线; 质量团队将实验室结果叠加于工艺变量之上。管理者则利用同一基础数据构建KPI仪表盘及绩效评估体系。
在数字化转型背景下,历史数据库作为核心数据基础设施,为统计过程控制(SPC)、预测质量、基于模型的优化、异常检测机器学习模型、实时质量预测软传感器以及高级过程控制强化学习算法等高级应用提供基础支撑。通过确保所有用户访问相同经过验证且时间同步的数据,历史数据库支持从控制室到企业管理层的一致决策。
借助dataPARC历史数据库,工艺数据得以保留原始精度,可轻松检索并获得上下文增强。工程师由此获得所需可见性,能够检测工艺漂移、评估优化项目,并自信地量化改进成效。
用例对比:历史数据库与SCADA系统实战解析
SCADA系统与历史数据库常协同运作,但在流程分析中的作用存在根本差异。SCADA提供短期态势感知能力,而历史数据库则具备长期分析功能。当工程师试图识别性能趋势、评估根本原因或验证流程改进效果时,这种差异尤为显著。
以下列举若干常见工业用例,展示两类系统在实践中的表现差异。
停机时间分析
使用SCADA时:操作员可观察设备跳闸或报警发生的时间,但历史数据通常仅限于当前或前一班次。事件上下文(如上下游工艺状态或操作员操作)往往缺失。缺乏历史数据支撑,难以区分机械故障、工艺故障或控制相关故障。
采用dataPARC Historian:停机事件自动记录精确时间戳,并可关联工艺数据、警报及操作员记录。工程师可按设备、产品等级或时间段筛选数据,识别重复性问题,并判定故障源于工艺波动、设备磨损还是人为干预。历史数据的精细解析支持频率分析、帕累托排序,并可关联产量或环境条件。这些分析可在车间现场或办公室完成——数据PARC历史数据库使数据更灵活、更易获取。
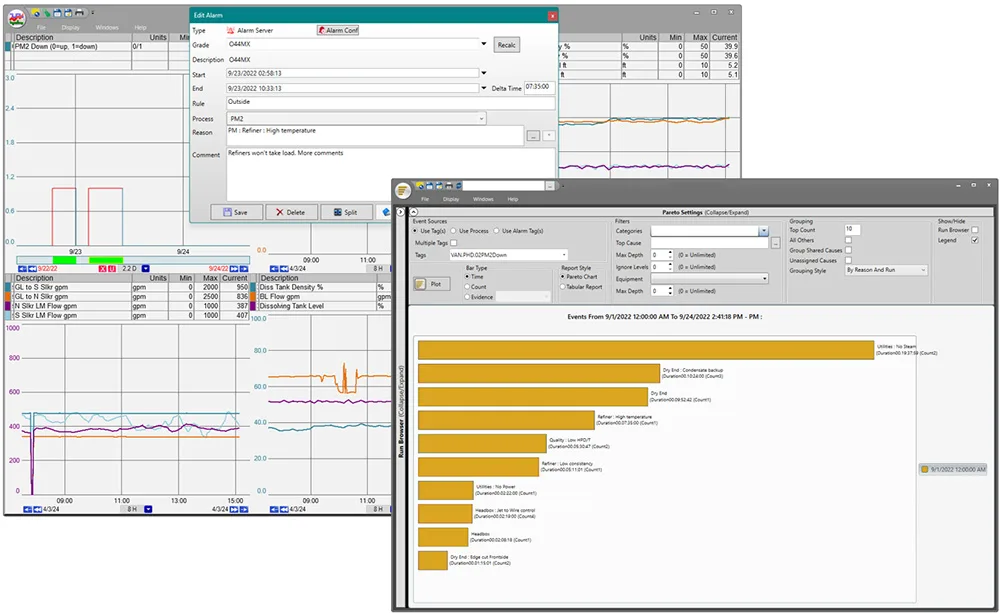
借助历史数据,用户可通过帕累托图回顾过往停机事件,识别最常见原因并降低未来发生概率。
质量故障排查
采用SCADA系统时:操作员可查看温度、压力、流量等实时参数,但跨产品批次或班次对比性能需手动导出数据并进行电子表格分析。SCADA趋势图常缺乏同步实验室数据或产品标识符,难以定位偏差起始时间或受影响批次。
采用dataPARC Historian:可高精度同步追踪质量与工艺数据趋势。用户可叠加实验室结果、产品代码及工艺设定值,精准定位偏差发生时间与条件。通过对比合格与不合格批次,工程师运用多元分析(PCA、PLS)识别与质量偏差相关性最强的工艺变量或组合,实现统计过程控制与前馈修正。
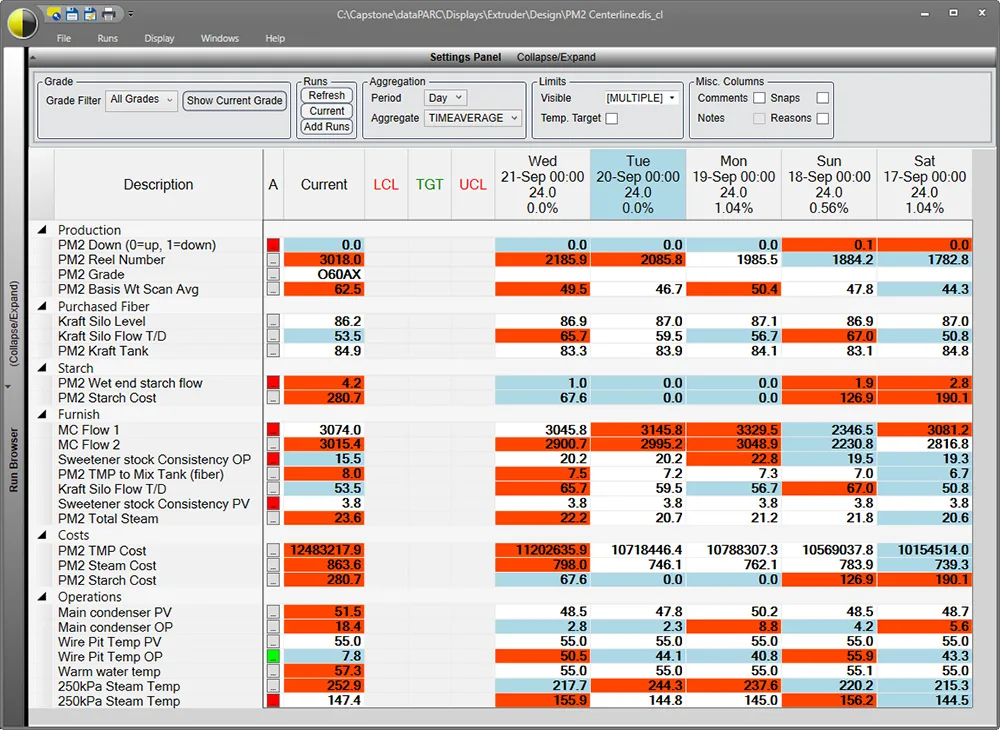
PARCview的中心线显示功能可用于质量控制,通过对比运行批次的历史数据,突出显示高于或低于平均值的参数,精准定位需重点关注的变量。
生产成本与能效管理
采用SCADA系统:能源或物料消耗通常实时监测,但成本核算需在后续业务系统中单独完成。生产单位成本的可视性有限,操作员无法即时获得工艺优化的反馈。
采用dataPARC Historian:可将能源消耗与工艺产量、物料使用量结合计算实时单位成本。历史分析能建立运行状态、设备性能与能耗强度的关联性,帮助工程师识别最高效运行区间,量化改进项目成效,并以实际成本数据论证工艺变更的合理性。
历史数据支持间隙追踪等计算,可对比当前与历史生产过程的运行表现。
班次间沟通
采用SCADA系统:班次交接高度依赖操作员记录或口头沟通。数据可见性仅限于HMI当前显示内容,趋势历史数据每日重置。前班次的重要上下文信息极易丢失,导致故障排查不一致且重复调查。
采用dataPARC Historian:所有用户可通过日志本等集成工具访问相同的趋势记录、报警信息及操作员注释。工程师能查阅前班次活动、确认纠正措施,并基于实际工艺数据分析重复性问题。这种一致性可减少停机时间,增强运营与工程团队的协同性。
尽管日志簿属于PARCview而非数据历史库的功能,仍彰显了历史数据及过往信息访问权限的重要性。
这些案例印证了核心原则:SCADA系统侧重控制,而历史库致力于理解。数据历史库等工具使团队能突破被动决策模式,迈向持续改进——每个数据点都将为工艺优化与可靠性提升贡献力量。
为何智能团队突破SCADA系统实现深度分析
随着流程工业向数据驱动决策转型,工程师们日益意识到仅靠SCADA系统无法满足现代制造的分析与诊断需求。SCADA系统在控制与安全领域不可或缺,但其架构设计从未考虑过处理当今工厂产生的海量、高速、多样化数据。
许多工厂试图通过将数据导出至电子表格或外部数据库,将SCADA系统充当临时历史数据库,但这种做法本身会引发新问题:数据源之间的时间同步性难以保证,元数据丢失,人工操作易产生错误。缺乏产品等级、设备状态或实验室结果等上下文信息,更导致长期分析过程繁琐且结果不一致。
专用历史数据库通过提供高分辨率、带上下文的时间序列数据,解决了上述难题。这些数据可用于高级分析、模型验证和持续改进,为深度分析奠定基础,并支持全厂范围的高级故障排除、模型开发及持续改进工作。若您的设施正寻求提升数据战略水平,部署历史数据库便是关键第一步——尤其当人工智能和第三方分析工具日益依赖丰富历史数据来驱动成果时。部署历史数据库是至关重要的第一步——尤其当人工智能与第三方分析工具日益依赖丰富历史数据驱动成果时。
突破SCADA系统局限还能支持更广泛的分析项目,例如:
- 预测性维护:利用长期振动、温度及运行时间数据预测设备故障
- 能源与资源优化:关联公用设施使用率与生产速率及环境条件
- 过程能力与变异性分析:运用SPC技术量化长期稳定性
- 生产可追溯性:将过程数据与批次记录、实验室结果及最终产品质量关联
通过采用历史数据库驱动架构,工厂可实现从事件响应向数据驱动优化的转型。工程师不再仅依赖操作员直觉,而是能获取经过验证、时间对齐的数据以支持定量分析。这加速了根本原因调查,缩短了故障排除周期,并为持续改进和人工智能驱动的项目提供了实证基础。
简言之,SCADA保障流程安全运行,而历史数据库则确保其高效智能地运转。
企业级数据历史库功能,成本仅为传统方案的零头。工业级时间序列数据采集与分析工具。
dataPARC 如何弥合鸿沟
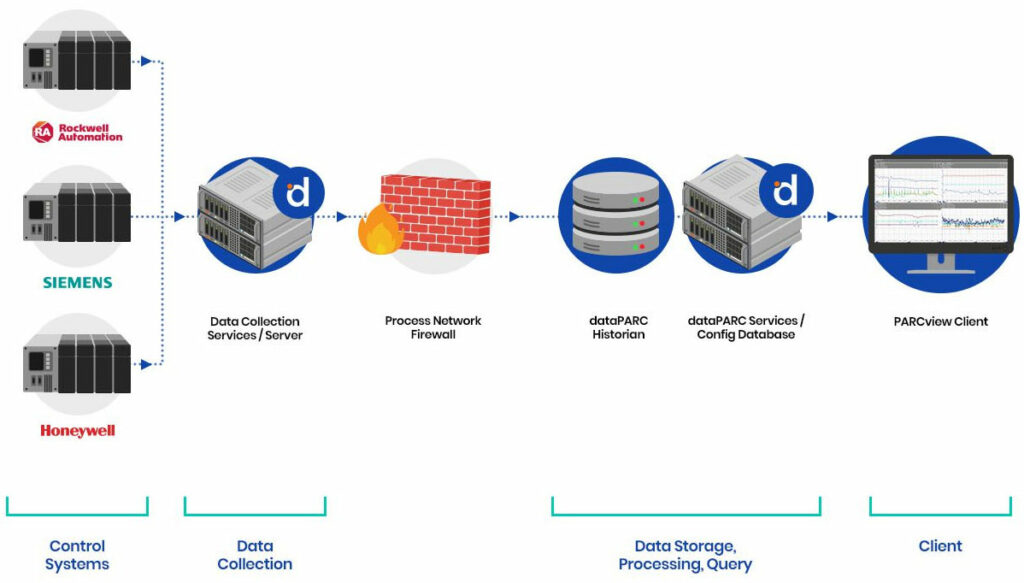
在多数制造环境中,SCADA系统是实时控制的中枢,而历史数据系统则是长期分析的基础。然而,当这两套系统无缝协作时,真正的价值才得以释放。dataPARC Historian通过融合高速数据采集与可扩展的上下文分析能力,跨越运营与工程领域,专为弥合这一鸿沟而设计。
dataPARC Historian支持OPC DA、OPC UA和gRPC等标准工业协议,使工程师无需复杂定制接口即可整合来自过程自动化、实验室及企业系统的信息。这种集成确保过程变量、实验室数据和生产指标均实现时间同步存储,并附带一致的元数据。
由此构建的集中化数据层支持多种应用场景:
- 运营团队可通过实时仪表盘和警报汇总提升效率。
- 工艺工程师可获取详细时间序列数据进行分析、模型验证及故障排查。
- 质量团队能关联产品数据与工艺条件。
- 管理层可清晰掌握关键绩效指标、生产效率及单位成本。
dataPARC不仅是数据仓库,更是情境分析平台。工程师无需导出数据至电子表格,即可应用产品特定限值、按批次或班次聚合数据,并跨时间段分析多变量趋势。
通过PARCview与dataPARC历史数据库协同运作,无需额外数据转换层即可实现预测性质量监控、早期预警及偏差分析。内置日志功能以结构化方式记录操作员与工程师的注释,将人工洞察与工艺数据融合,形成更完整的运行记录。
不同于多数需专业IT支持配置的历史数据库和可视化系统,dataPARC专为工程师操作而设计。用户可通过直观界面配置标签、构建仪表盘并分析数据,该界面完全契合工程师对工艺关联性的思维模式。这种易用性确保跨部门快速普及与持续应用。
实践中,dataPARC成为控制与洞察的桥梁。它将SCADA系统的即时性与历史数据库的分析深度相融合,赋能团队不仅能洞察现状,更能理解根源。通过实时可视化与历史数据的结合,制造商可优化工艺性能、提升产品质量,实现更智能的数据驱动运营。
高速可扩展数据历史库,成本大幅降低。立即体验dataPARC Historian。
 :选择与您共同成长的工具
从基于SCADA的控制到历史数据库驱动的洞察,标志着工艺数据价值与应用方式的变革。SCADA系统仍是实时控制和操作安全的核心,但其设计初衷从未涵盖现代工艺优化所需的大规模数据存储、情境化处理及分析能力。
对工艺工程师而言,长期可视性至关重要。缺乏历史背景数据将无法验证性能提升、识别渐进式工艺漂移,也无法支持基于模型的控制和预测分析等数据驱动型举措。历史数据库通过确保每个标签、警报和事件均被存储、时间同步且可供分析,为这些需求奠定基础。
数据数据历史库与PARCview的结合,通过在单一环境中集成实时可视化、情境分析和跨系统连接,进一步拓展了这一能力。工程师可无缝切换于实时过程监控与历史数据回溯、根本原因分析与成本质量评估之间,全程保持数据完整性与情境关联性。
选择能随业务规模扩展的工具至关重要。今日用于采集高频数据的系统,必须同时支持明日的分析需求与数字化转型目标。通过dataPARC平台,团队既能保障运营可靠性,又能实现长期改进,使过程数据不仅成为历史事件的记录,更成为持续学习与优化的资源库。
常见问题:历史数据系统与SCADA系统的对比
- 为何长期历史数据对工艺优化至关重要?
长期数据使工程师能够检测缓慢的工艺漂移、识别反复发生的停机事件,并验证工艺变更的影响。缺乏这些数据,持续改进将沦为猜测。高分辨率历史数据支持统计过程控制、预测性质量分析和基于模型的决策,这些都是先进制造战略的核心要素。 - 历史数据系统如何与SCADA及其他工厂系统集成?
历史数据系统通过OPCDA、OPCUA、OPCHDA等标准工业协议连接SCADA、DCS和PLC系统。可视化工具如PARCview可与历史数据系统、实验室信息系统、ERP数据库及维护系统对接。这种集成使工程师能整合生产数据与质量、成本及资产信息,实现全流程可视化。 - 数据历史库能实现哪些SCADA无法完成的分析?
借助完整的历史数据库,团队可通过PARCview或第三方集成开展多元化分析:执行多变量相关性分析、能耗强度分析及预测模型验证;创建整合工艺、实验室与业务数据的统一仪表盘。这些能力使数据从监测工具蜕变为持续改进、可靠性分析及战略决策的基石。 - 与SCADA数据存储相比,历史数据库在性能上有哪些优势?
历史数据库采用专用的压缩、索引和检索算法,可高效存储海量时间序列数据。即使查询多年数据集,响应时间仍接近实时。这使工程师能够跨长期区间分析趋势,且不会出现性能下降或细节丢失。 - dataPARC历史数据库如何提升操作员与工程团队的协作效率?
dataPARC Historian提供高精度数据、仪表盘及日志本等情境化工具的共享访问权限。操作员、工程师和质量团队可共同查看同一历史记录,审阅标注趋势,并将工艺数据与注释或事件关联。这种统一可视性消除了沟通鸿沟,确保跨班次和跨部门的一致性。这是您的数据,现场所有需要访问数据的人员都应获得访问权限。
Building The Smart Factory
A Guide to Technology and Software in Manufacturing for a Data-Drive Plant






