Dans les industries de procédés, l’optimisation est la clé de l’efficacité. Et l’efficacité est ce qui mène au profit – permettant aux fabricants de produire plus et de gaspiller moins. Pour optimiser leurs procédés, de nombreux fabricants utilisent une combinaison de data historien de séries temporelles et de logiciels de visualisation de données. dataPARC et PI sont deux des leaders dans ce domaine, et dans cet article nous allons comparer dataPARC par rapport à PI et mettre en avant certains des avantages de dataPARC sur PI en tant que système de gestion des informations de procédés.
Découvrez les outils d’analyse des données de procédé en temps réel de dataPARC et voyez comment de meilleures données peuvent mener à de meilleures décisions.
dataPARC par rapport à PI : Similarités
dataPARC et PI existent depuis des décennies et disposent de grandes bases d’installations représentées par des fabricants majeurs à travers le monde.
dataPARC et PI :
- Proposent un data historien en temps réel
- Utilisent un fichier plat binaire indexé en cluster pour stocker l’historique
- Disposent d’une structure d’actifs pour gérer la complexité de grandes sources de données disparates
- Proposent de nombreux outils d’analyse et de visualisation attendus : tendances, graphiques, rapports
- Peuvent se connecter à divers systèmes de contrôle pour collecter des données de séries temporelles en temps réel
- Utilisent une fonction de stockage et de transfert en cas de perte de connectivité des données
- Peuvent fonctionner avec des systèmes à très grand nombre de tags
Voyons maintenant plus en détail leurs différences et comment dataPARC se distingue.
dataPARC par rapport à PI : Différences
Coût
Autant commencer par ce qui sera l’un des critères clés lors de l’évaluation de ces deux data historiens et outils de visualisation de données de procédés.
Pour faire court, le coût total de possession de dataPARC est inférieur par rapport aux autres solutions similaires de l’industrie. Le coût initial et les coûts récurrents sont tous deux nettement inférieurs à ceux du PI System.
Utilisateurs illimités
Une raison clé à cela est le modèle de licence illimitée de dataPARC, qui en fait un excellent choix pour les organisations souhaitant mettre les données de production à disposition des décideurs à tous les niveaux de l’usine sans avoir à acheter des licences supplémentaires.
PI utilise un modèle de tarification par utilisateur. Cela fonctionne pour les petites organisations où seules quelques personnes ont besoin d’accéder à la plateforme, mais pour les grandes organisations ou les déploiements d’entreprise, le coût augmente rapidement.
Avec dataPARC, toute personne ayant besoin d’accéder aux données peut y accéder sans coût supplémentaire – donnant à chaque employé le pouvoir de prendre des décisions basées sur les données.
Vous cherchez une alternative au data historien de PI ? Obtenez un data historien d’usine d’entreprise à une fraction du coût. Découvrez l’Historien PARCserver de dataPARC.
Expérience utilisateur
Lorsque l’on demande aux clients quels sont les 3 à 5 principaux avantages de dataPARC, la facilité d’utilisation arrive toujours en tête de liste. La complexité réduite du système dataPARC permet même à la personne la moins « à l’aise avec l’informatique » de commencer à créer du contenu et à en tirer de la valeur, ce qui entraîne une large adoption des outils au sein de l’organisation.
Bien que dataPARC propose de nombreuses fonctionnalités, un nouvel utilisateur peut apprendre à rechercher des tags, à faire des tendances et à naviguer en quelques minutes. À partir de là, les utilisateurs apprennent rapidement qu’ils peuvent consulter les statistiques de tendance, gérer les événements d’alarme, exporter des données, créer des affichages tels que X/Y Plot, Histogramme ou Pareto et bien plus encore, tout cela depuis le menu clic droit.
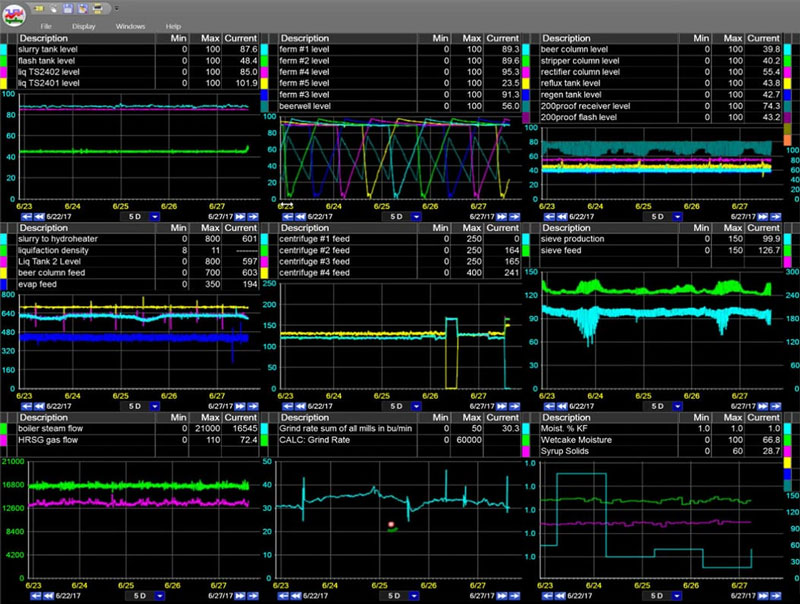
Les outils de tendances de dataPARC sont depuis longtemps reconnus par les clients comme la solution de tendance numéro 1 dans l’industrie. Les capacités de tendance de dataPARC sont plus rapides et bien supérieures à celles des autres et s’adaptent mieux aux fonctions pratiques.
Aucun autre logiciel ne permet de créer aussi rapidement une matrice de tendances, avec un simple glisser-déposer depuis le Navigateur de Tags ou les affichages.
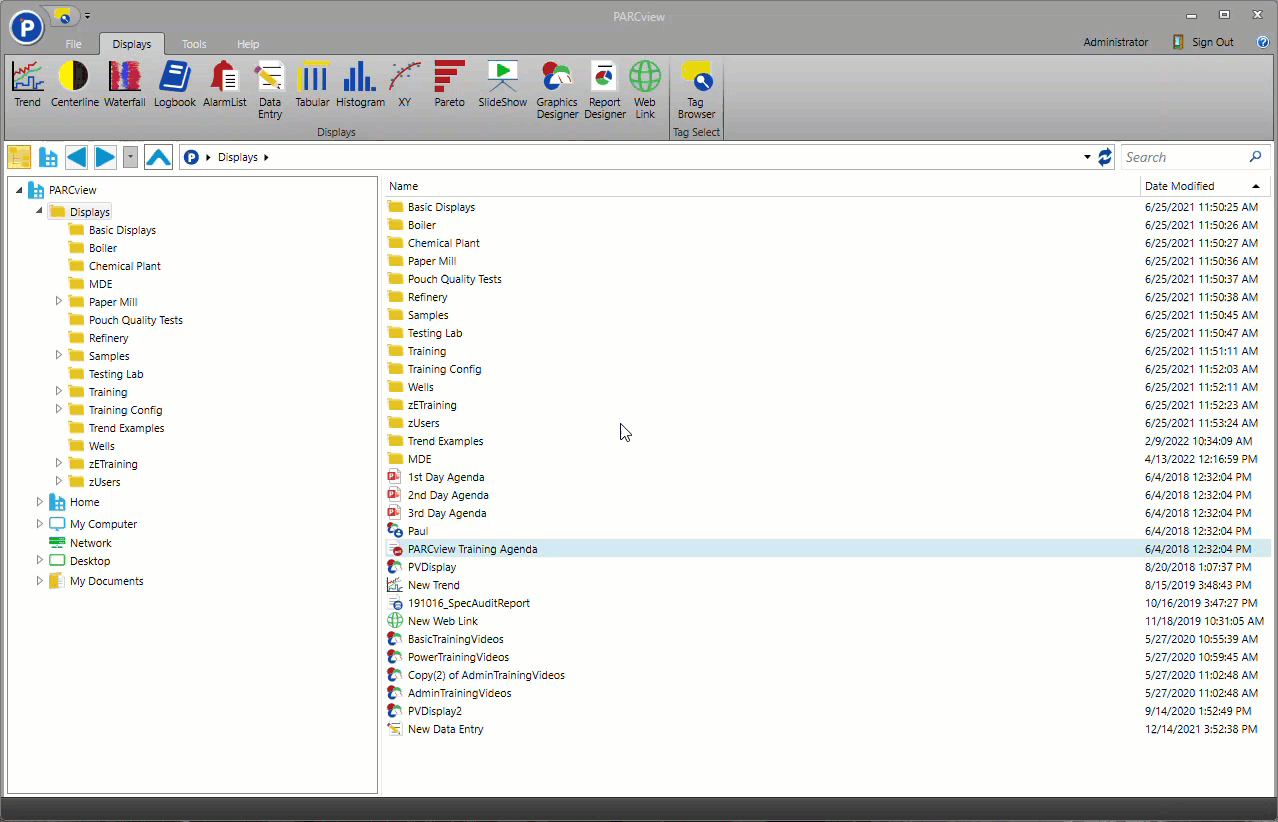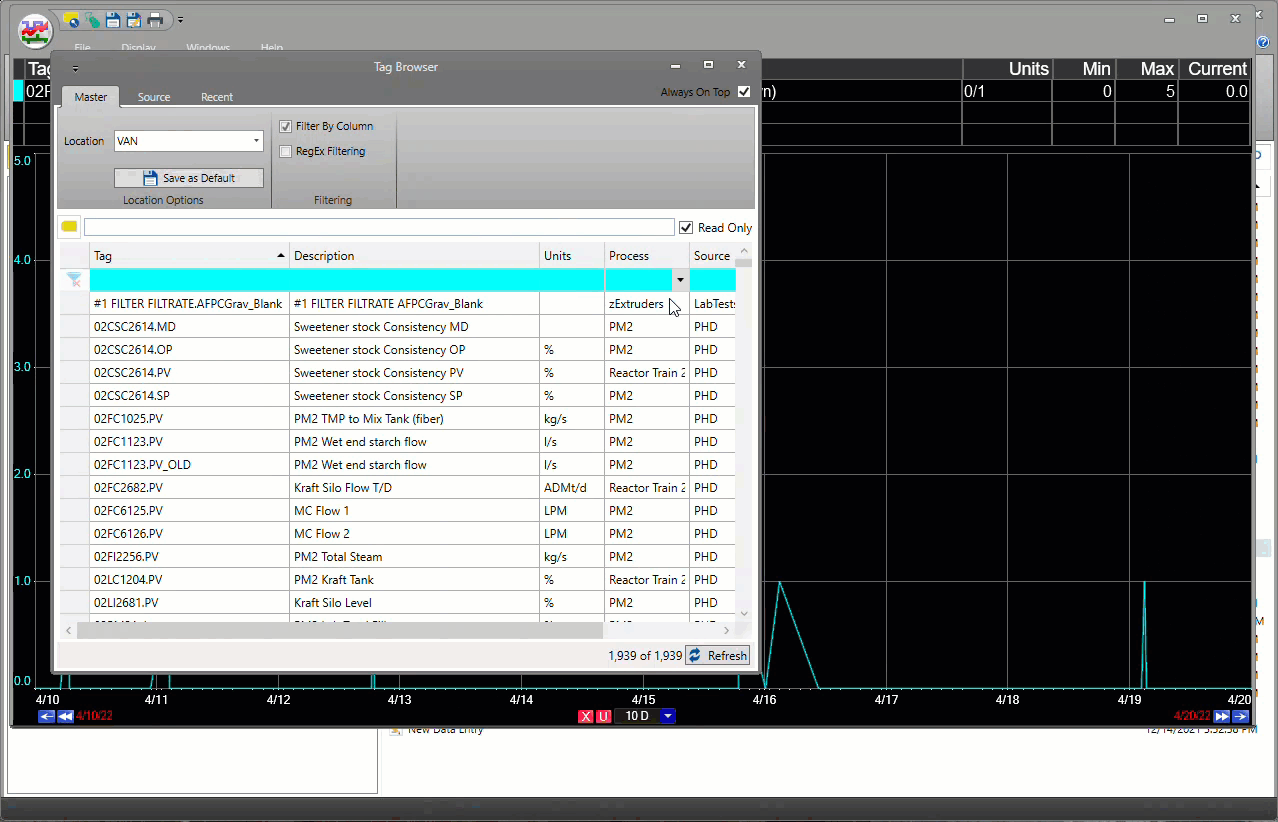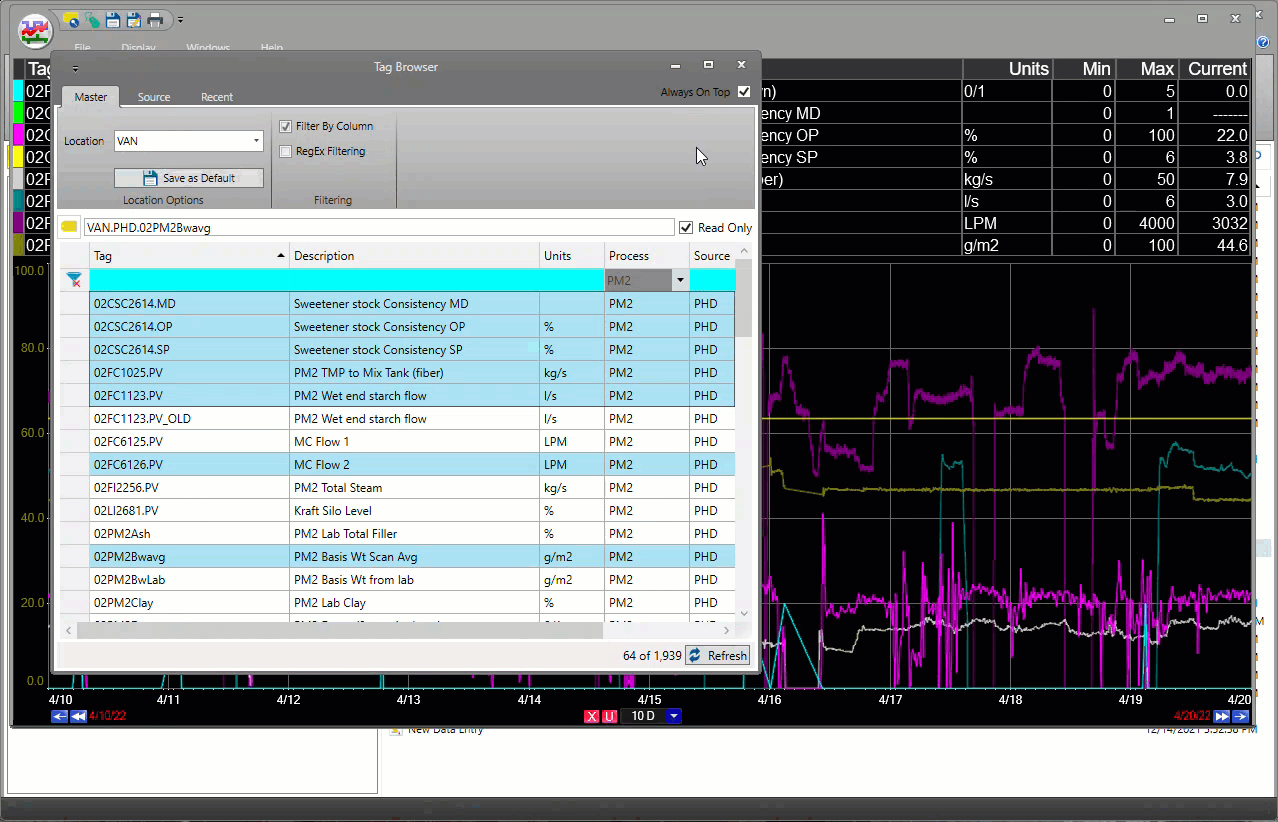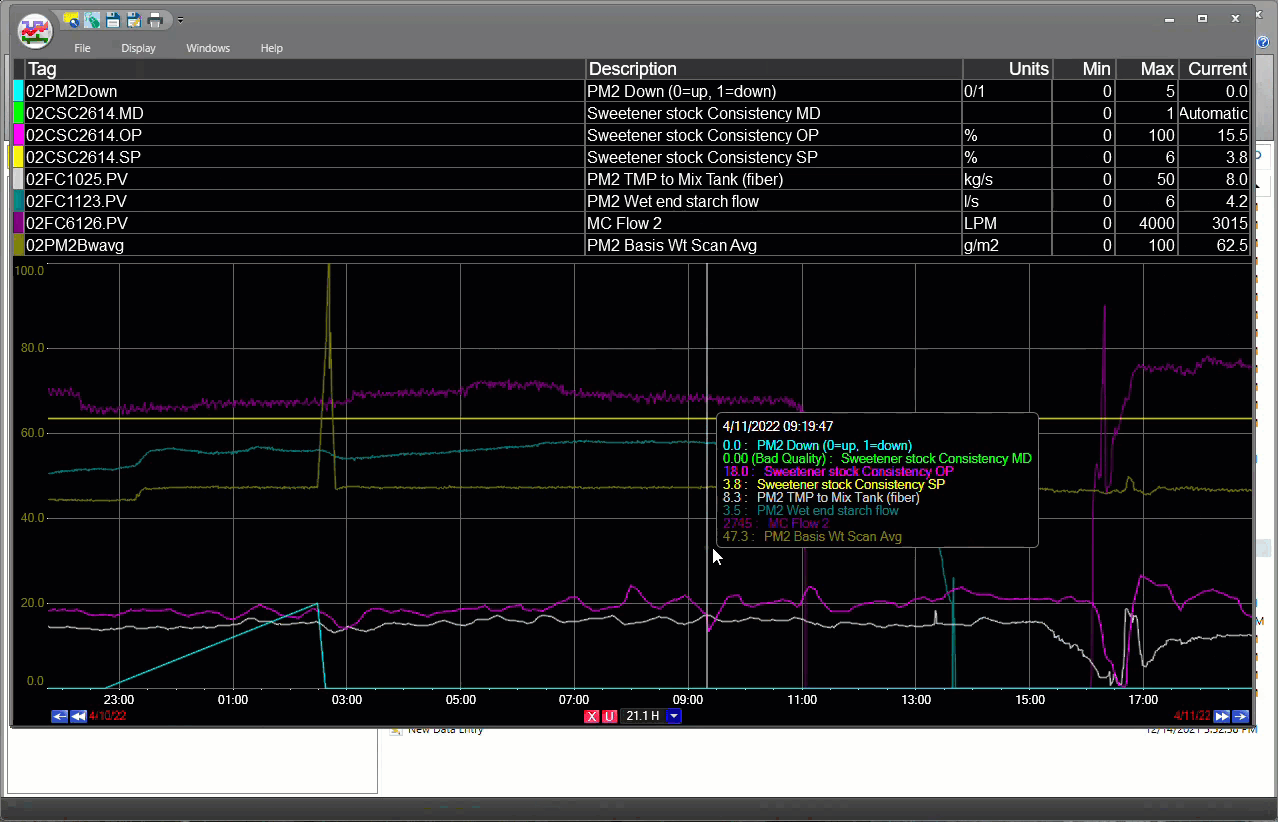
dataPARC rend la recherche et la mise en tendance des données de tags extrêmement facile.
De nombreuses organisations qui utilisaient le PI Historian et ProcessBook ont depuis choisi d’ajouter dataPARC « par-dessus » leur PI Historian simplement pour PARCview ; les outils de visualisation et la facilité d’utilisation parlent d’eux-mêmes.
Analyse diagnostique
Comme mentionné précédemment, l’application de tendance de dataPARC est considérée comme la meilleure de l’industrie. Non seulement pour sa facilité d’utilisation et son accès rapide aux outils d’analyse, mais aussi pour sa rapidité.
Tendance
dataPARC utilise une stratégie de vitesse de données délibérée avec plusieurs composants, dont un Performance Data Engine (PARCpde) intégré pour accélérer l’accès aux données pour l’utilisateur. L’objectif est de répondre et de dépasser la « vitesse de la pensée » de l’utilisateur. PARCpde est une partie fondamentale de l’ensemble du système dataPARC.
Des tests de vitesse comparant dataPARC par rapport à PI et d’autres historiens contemporains ont montré que dataPARC est de 10X à 50X plus rapide pour restituer de grands ensembles de données ou des historiques longs à l’utilisateur.
Plusieurs entreprises sont passées à dataPARC en partie à cause de la rapidité des données. dataPARC utilise également une archive agrégée et une archive de consolidation dans son architecture, ce qui réduit considérablement le temps perdu lors de la résolution de problèmes ou de l’analyse d’opportunités.
Depuis la tendance, les utilisateurs peuvent lancer une grille de statistiques rapides, générer un nouveau graphique X/Y ou un affichage Histogramme. Chaque graphique récupère les tags depuis la tendance, ainsi les utilisateurs n’ont pas à les rechercher à nouveau dans le Navigateur de Tags.
Le graphique X/Y configure deux tags pour la comparaison et une droite de meilleure adéquation peut être générée – linéaire, polynomiale, etc. La formule générée à partir de l’ajustement peut être intégrée dans une tendance ou un autre affichage. PI peut également générer des graphiques X/Y, mais ils sont créés à partir de zéro et aucune droite de meilleure adéquation n’est générée.
Add-in Excel
L’add-in Excel de dataPARC a été conçu pour une grande facilité d’utilisation et rapidité.
PI DataLink et l’add-in Excel de dataPARC disposent tous deux de fonctions en cellule permettant d’importer directement des données dans Excel. Cependant, le dataPARC Excel Add-in propose de nombreuses autres fonctions.
Il existe une feuille permettant d’importer plusieurs tags sur la même plage de temps sans avoir à gérer de formules. Les utilisateurs peuvent importer des listes de tags à partir d’affichages dataPARC déjà créés au lieu de rechercher à nouveau les tags.
Au-delà de la valeur ajoutée par les outils add-in Excel hérités, celui de dataPARC se distingue par les points suivants :
- Glisser des groupes de tags/données dans Excel depuis plusieurs sources de données
- Filtrer les données selon plusieurs valeurs de tags
- Génération de matrices de corrélation croisée/R2
- Graphiques CUSUM et MSR
De plus, les utilisateurs peuvent afficher des données basées sur des séries temporelles depuis Excel dans les tendances et affichages PARCview. Cela peut être utilisé pour mettre en tendance ou comparer des données externes à l’entreprise juste à côté des données de procédés.
Gestion des opérations
La gestion des opérations en temps réel est nécessaire pour maintenir une usine à son efficacité maximale et pouvoir réagir rapidement aux excursions de procédés qui entraînent des temps d’arrêt non planifiés ou des pertes de produit.
Cela est facilité par dataPARC de différentes manières :
- Affichages graphiques de procédés
- Tableaux de bord KPI et données de laboratoire
- Outils de saisie manuelle de données (MDE)
- Rapports automatisés
- Alarmes et notifications de procédés
- et plus encore
En comparant dataPARC par rapport à PI, les deux permettent la création de tableaux de bord graphiques dynamiques et riches en informations, mais seul dataPARC propose l’affichage Ligne Centrale.
Ligne Centrale
La Ligne Centrale est un outil de surveillance puissant unique à dataPARC. Il s’agit d’un affichage en temps réel qui rapporte des statistiques basées sur les runs pour les tags. Les runs peuvent être basés sur le Grade ou le Temps, et les statistiques incluent la moyenne temporelle, l’écart type, le CpK, le min, le max, etc.
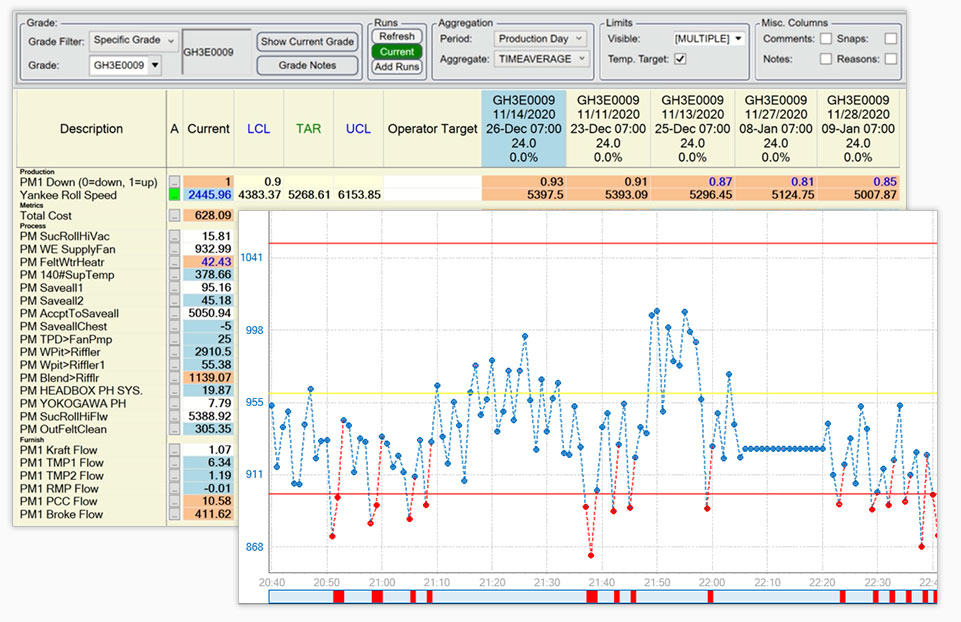
L’affichage Ligne Centrale présente les données pour des périodes ou des runs afin de garantir que les conditions de procédés sont identiques d’un run à l’autre.
Le but d’un affichage Ligne Centrale est d’aider à déterminer les meilleurs réglages opérationnels pour la production, et de s’assurer que ces réglages sont normalement utilisés pendant la production.
La Ligne Centrale est l’un des puissants outils d’analyse de données de dataPARC pour lesquels il n’existe pas d’équivalent PI.
Alarmes et notifications
Le système d’alarme et de notification de dataPARC peut envoyer des emails, des notifications par SMS ou déclencher des workflows lorsqu’une alarme est détectée ou fermée. Une fois une alarme détectée, un événement d’alarme est créé. Ces événements peuvent être visualisés et validés dans une Tendance, une Ligne Centrale, un graphique ou une liste d’alarmes. Les utilisateurs peuvent valider l’événement en assignant une raison depuis l’arbre des raisons et/ou en saisissant un commentaire sur l’événement. Une analyse rapide peut être réalisée dans dataPARC avec le graphique de Pareto pour déterminer les principales raisons enregistrées pour une alarme ou créer un rapport tabulaire trié par raison avec tous les commentaires visibles.
De même, les notifications PI peuvent créer des cadres d’événements et envoyer des notifications. Une fois les cadres d’événements détectés et une raison assignée, les utilisateurs peuvent voir ces données sous forme de tableau dans PI Vision, mais une analyse ou un reporting supplémentaire doit être effectué dans le PI Excel Add-in DataLink. L’add-in Excel de dataPARC propose également des fonctionnalités pour importer les données d’événements d’alarme.
Plus de fonctionnalités du dataPARC Excel Add-in sont présentées dans la section suivante.
Saisie manuelle de données (MDE)
L’affichage MDE de dataPARC est rapide à configurer et permet aux utilisateurs de saisir et d’enregistrer des données manuelles dans la base de données plutôt que sur papier ou dans Excel.
Les données saisies manuellement sont représentées par des tags, elles peuvent donc être utilisées dans les tendances, tableaux de bord et affichages PARCview comme n’importe quel autre tag.
Besoin de fournir de meilleures données à vos ingénieurs procédés ? Découvrez nos outils d’analyse de procédés en temps réel et voyez comment de meilleures données peuvent mener à de meilleures décisions.
Calculs
Lorsque les utilisateurs n’ont pas le tag parfait pour gérer un procédé, un tag de calcul ou une saisie manuelle de données (MDE) est souvent utilisé. dataPARC et PI peuvent tous deux effectuer des calculs simples tels que l’addition de tags, des instructions If/Then ou des conversions d’unités.
Avec PI Vision, PI Analytics ne prend plus en charge le scripting VB. Le scripting VB ouvre la porte à des solutions personnalisées et dataPARC exploite le scripting VB pour des applications telles que la lecture de bases de données, le parsing de fichiers, les appels de services web, et bien plus encore.

Modélisation des actifs
L’Asset Hub de dataPARC et l’Asset Framework (AF) de PI proposent tous deux des moyens de structurer et de contextualiser les données de séries temporelles en organisant les tags autour des actifs physiques. Bien que PI AF soit puissant, il nécessite souvent une configuration plus complexe à l’aide d’outils externes et de scripts. En revanche, Asset Hub est conçu pour les ingénieurs et opérateurs, offrant une interface plus intuitive, en pointer-cliquer, pour construire et maintenir des hiérarchies d’actifs sans formation spécialisée.
Ce qui distingue Asset Hub, c’est son intégration étroite avec les outils de tendances, tableaux de bord et alarmes de dataPARC. Les utilisateurs peuvent rapidement passer d’une vue globale de l’usine à des actifs individuels et voir en un seul endroit les KPI en temps réel, les tendances historiques et les limites de performance.
Accès web et flexibilité
En matière d’accès web, les utilisateurs du PI System sont limités à PI Vision, un outil entièrement basé sur le web. Bien qu’il offre un moyen centralisé de visualiser les données, il n’a pas d’équivalent sur poste de travail, ce qui peut être limitant pour les utilisateurs qui préfèrent ou nécessitent une application locale plus robuste. Certains des inconvénients ont été évoqués dans les sections précédentes, y compris pour les calculs.
dataPARC propose à la fois une application de bureau complète (PARCview) et une version basée sur navigateur. Cette approche hybride donne aux équipes la flexibilité de choisir le meilleur outil pour la tâche, qu’elles soient en salle de contrôle, sur un ordinateur portable ou en télétravail.
Analyse prédictive
PARCmodel de dataPARC propose un certain niveau d’analyse prédictive avec des capacités de modélisation PLS (Partial Least Square) et PLC (Principal Component Analysis).
PLS
Le package PLS a été décrit par l’un des meilleurs ingénieurs en modélisation pratique au monde comme « …de loin, meilleur que tout ce que j’ai pu voir auparavant. » Dans l’industrie de transformation, l’une des applications de la modélisation PLS est la création de prédicteurs de propriétés inférentielles (IPP).
Des ingénieurs de contrôle dans des sociétés d’exploitation rapportent que la génération d’un modèle PLS pour un IPP peut prendre plus de 8 heures à re-modéliser (et plus pour le modèle initial) en utilisant plusieurs outils et des activités hors ligne. dataPARC intègre tout dans un seul outil et l’effort de re-modélisation peut être aussi court que 5 minutes.
Cette génération rapide de modèles permet de générer plusieurs solutions à comparer pour trouver la meilleure option. La rapidité de re-modélisation permet une application et un bénéfice plus larges du PLS. Les méthodes d’ingénierie pratiques et même les « intuitions » de procédés peuvent désormais être validées rapidement par une session mathématique PLS en 2 à 5 minutes.
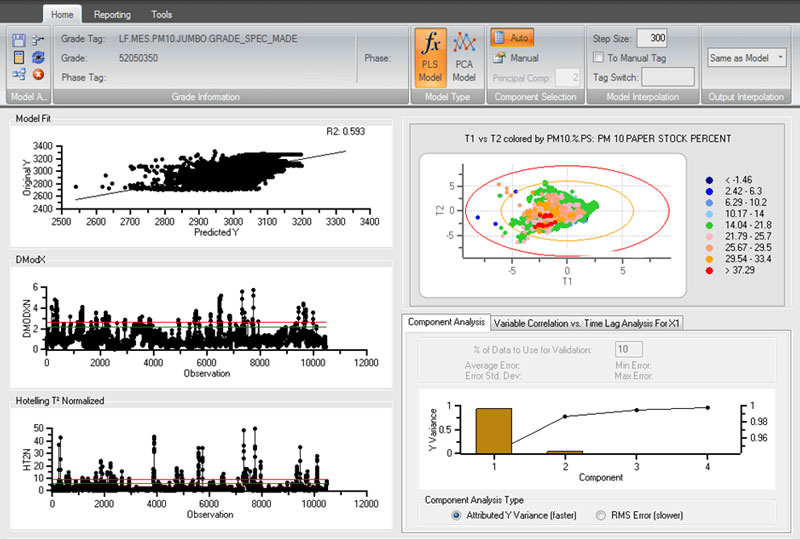
Outils de modélisation prédictive de dataPARC
dataPARC permet un gain de temps considérable, un meilleur environnement d’apprentissage, une meilleure collaboration, des applications plus utiles – tout cela accélère la création de valeur pour les principaux moteurs de l’entreprise.
PCA
PCA utilise les mêmes avantages de modélisation que le PLS de dataPARC, permettant une génération de modèles facile. La différence entre les deux méthodes de modélisation est que le PLS cherche à modéliser et reproduire une seule variable en utilisant des variables adjacentes comme entrées du modèle. PCA ne modélise pas une seule variable mais modélise l’ensemble d’un procédé.
La valeur apparaît lors de la comparaison du procédé actuel avec le procédé modélisé. PCA donne à l’utilisateur la possibilité de savoir quand le procédé actuel est déviant (par rapport au procédé modélisé) et identifie la/les variable(s) de procédé « en cause ».
PCA utilise deux paramètres (également disponibles pour le modèle PLS) : DMODX (erreur du modèle) et HT2N (Hotelling T2 Normalisé – hors norme). Les variables d’entrée du modèle PCA sont toutes notées et le personnel peut voir quelle(s) variable(s) cause(nt) le problème. PCA peut être utilisé comme système d’alerte précoce pour aider les opérations à détecter un problème avant qu’il ne survienne.
PARCmodel est sous licence séparée mais intégré à PARCview et facilement accessible dans le menu clic droit de la tendance. PI ne dispose pas d’outils d’analyse similaires.
Vous cherchez à remplacer ProcessBook ? Découvrez pourquoi PARCview est considérée comme la meilleure alternative à ProcessBook.
Développement et support centrés sur le client
Chez dataPARC, la priorité est donnée au client et à ses besoins réels, urgents et pratiques. La stratégie de dataPARC implique une grande attention portée aux besoins du client et une résolution rapide des problèmes.
dataPARC emploie de nombreux experts métiers occupant des rôles clés de support en ingénierie de procédés pour des sociétés d’exploitation dans l’industrie. Au fil des années, les fonctionnalités utilisateurs et l’architecture globale du système de dataPARC ont été façonnées par les experts métiers et les clients. dataPARC est conçu par et pour les utilisateurs finaux.
Chez dataPARC, nous vendons plus qu’un logiciel, nous proposons nos services pour aider à créer des tendances, des graphiques et d’autres affichages afin de lancer rapidement votre système. Nos ingénieurs et notre support sont disponibles pour aider à la mise en œuvre de nouveaux projets et assurer un support continu.
Avec PI, pour obtenir les mêmes affichages, les clients doivent faire appel à un prestataire tiers. dataPARC est un guichet unique.
Conclusion
dataPARC et PI ont beaucoup en commun, cependant dataPARC a l’avantage là où cela compte – expérience utilisateur, rapidité des données et coût. dataPARC est simple, rapide et efficace.
Les avantages de dataPARC par rapport à PI continuent de croître à chaque nouvelle fonctionnalité et mise à jour. Des fonctionnalités pilotées par les utilisateurs et les clients.





