Dans cet article, nous explorons les différences entre les systèmes historiques et les systèmes SCADA, et expliquons pourquoi il ne s’agit pas de choisir l’un plutôt que l’autre. Nous allons plutôt détailler comment ces technologies fonctionnent ensemble pour créer un écosystème complet de données opérationnelles, permettant aux équipes de surveiller les processus en temps réel et d’analyser les données historiques afin d’apporter des améliorations à long terme.
Historique de données rapide et évolutif à un coût réduit. Découvrez l’historique dataPARC
Le passage du contrôle à la connaissance
Les systèmes SCADA traditionnels sont conçus dans un but principal : le contrôle de supervision et la surveillance en temps réel. Ils agrègent les données de processus provenant des PLC, des RTU et des systèmes DCS, visualisent les variables clés et permettent aux opérateurs de maintenir des conditions de production stables. Le SCADA excelle dans la réponse quasi instantanée aux alarmes, aux changements de points de consigne et aux verrouillages, garantissant ainsi la sécurité et la fiabilité au niveau des équipements.
À mesure que la fabrication évolue vers des opérations basées sur les données, les attentes envers les systèmes d’information des usines se sont accrues. Les ingénieurs doivent non seulement voir ce qui se passe actuellement, mais aussi comprendre comment et pourquoi cela s’est produit, et prédire ce qui va se passer ensuite. Cela nécessite des données de processus à haute résolution et à long terme qui peuvent être analysées sur plusieurs équipes, lots ou campagnes de production afin de mettre en évidence des tendances et des corrélations que les données SCADA à court terme ne peuvent pas fournir.
La conservation des données SCADA s’étend généralement sur plusieurs heures, voire plusieurs jours. De nombreux systèmes hérités écrasent les données après 48 à 72 heures ou les sous-échantillonnent à des moyennes d’une minute, perdant ainsi les détails des signaux à haute fréquence essentiels pour identifier les perturbations transitoires ou les comportements oscillatoires. Cet historique de données limité est insuffisant pour les analyses avancées, les investigations sur les causes profondes ou les modèles d’apprentissage automatique qui reposent sur des données chronologiques continues et ininterrompues. De plus, les données ne sont accessibles qu’à un nombre limité de clients dans la salle de contrôle. Cela limite encore davantage les analyses et la possibilité d’utiliser ses propres données.
Un historien de processus, tel que dataPARC Historian, est spécialement conçu pour combler cette lacune. Il capture en continu des données chronologiques en pleine résolution et les stocke efficacement sans date de fin, en préservant le contexte et la granularité. Cela permet aux ingénieurs de suivre les tendances du comportement des processus sur plusieurs années, de corréler les données de production avec les mesures de qualité et d’analyser l’efficacité énergétique ou le débit au fil du temps.
En élargissant le champ d’action du contrôle en temps réel à la vision à long terme, un historien transforme les données d’une nécessité opérationnelle en un atout stratégique. Il devient le fondement de l’amélioration continue, de l’analyse prédictive et de décisions de fabrication plus intelligentes.
Ce qui différencie un historien de séries chronologiques
Alors que les systèmes SCADA sont conçus pour la surveillance et le contrôle en temps réel, les historiens de processus sont conçus pour la collecte de données à long terme, le stockage à haute fréquence et l’analyse avancée. La distinction ne réside pas seulement dans la conservation des données, mais aussi dans leur intégrité, leur accessibilité et leur contexte.
Les historiens capturent et conservent des données chronologiques haute résolution provenant de centaines ou de milliers de balises de processus sur plusieurs systèmes. Plutôt que de sous-échantillonner ou de remplacer les anciennes valeurs, un historien ajoute continuellement des données, en conservant à la fois les ensembles de données brutes et agrégées. Cette approche permet aux ingénieurs d’analyser les conditions du processus à tout moment sans perdre en granularité.
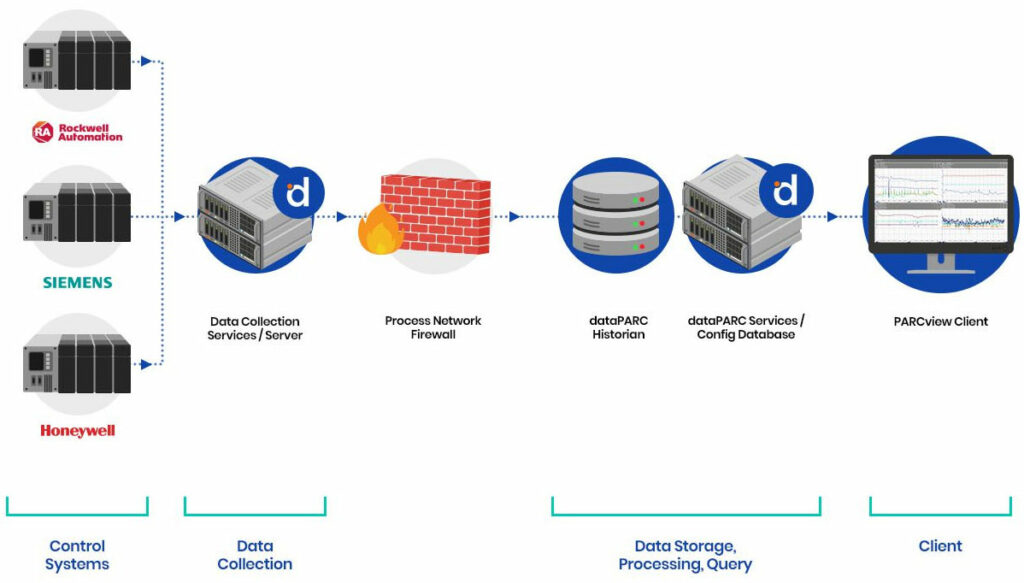
Alors que le SCADA assure le contrôle et les alarmes de l’opérateur, l’historique capture les données chronologiques complètes derrière chaque tendance, événement et décision, permettant ainsi une analyse approfondie et une amélioration des performances.
Contrairement au SCADA, qui s’adresse principalement aux opérateurs, les historiques sont utilisés par un large éventail de rôles au sein de l’usine. Les ingénieurs de processus analysent les tendances et comparent les conditions entre les lots ou les qualités de produits. Les équipes chargées de la fiabilité corréler les données relatives aux temps d’arrêt avec les profils de vibration ou de température. Les équipes chargées de la qualité superposent les résultats de laboratoire aux variables de processus. Les responsables utilisent les mêmes données sous-jacentes pour les tableaux de bord des indicateurs clés de performance et les évaluations de performance.
Dans le contexte de la transformation numérique, l’historique sert d’infrastructure de données centrale. Il fournit la base pour des applications avancées telles que le contrôle statistique des processus (SPC), la qualité prédictive, l’optimisation basée sur des modèles et les modèles d’apprentissage automatique pour la détection des anomalies, les capteurs logiciels pour la prédiction de la qualité en temps réel et les algorithmes d’apprentissage par renforcement pour le contrôle avancé des processus. En garantissant à tous les utilisateurs l’accès aux mêmes données validées et synchronisées, l’historique favorise une prise de décision cohérente, de la salle de contrôle à la direction de l’entreprise.
Avec dataPARC Historian, les données de processus sont conservées dans leur fidélité d’origine, facilement récupérables et enrichies contextuellement. Les ingénieurs bénéficient de la visibilité nécessaire pour détecter les dérives de processus, évaluer les projets d’optimisation et quantifier les améliorations en toute confiance.
Comparaison des cas d’utilisation : historiens vs SCADA en action
Les systèmes SCADA et historiens fonctionnent souvent ensemble, mais leurs rôles dans l’analyse des processus diffèrent fondamentalement. Le SCADA fournit une connaissance de la situation à court terme, tandis que l’historien offre une capacité d’analyse à long terme. La distinction devient claire lorsque les ingénieurs tentent d’identifier les tendances de performance, d’évaluer les causes profondes ou de valider les améliorations des processus au fil du temps.
Vous trouverez ci-dessous plusieurs cas d’utilisation industriels courants qui mettent en évidence les performances de chaque système dans la pratique.
Analyse des temps d’arrêt
Avec SCADA : les opérateurs peuvent observer quand un équipement se déclenche ou qu’une alarme se produit, mais les données historiques sont souvent limitées à l’équipe actuelle ou précédente. Le contexte de l’événement, tel que les conditions du processus en amont et en aval ou les actions de l’opérateur, est généralement absent. Sans cet historique, il devient difficile de faire la différence entre les défaillances mécaniques, celles liées au processus ou celles liées au contrôle.
Avec dataPARC Historian : les événements de temps d’arrêt sont automatiquement enregistrés avec des horodatages précis et peuvent être corrélés avec les données de processus, les alarmes et les notes des opérateurs. Les ingénieurs peuvent filtrer par équipement, qualité du produit ou période afin de détecter les problèmes récurrents et de déterminer si les défaillances sont dues à la variabilité des processus, à l’usure des équipements ou à l’intervention humaine. La résolution historique permet une analyse de fréquence, un classement de Pareto et une corrélation avec le taux de production ou les conditions ambiantes. Cela peut être fait dans l’usine ou dans un bureau ; les données sont plus polyvalentes et accessibles avec dataPARC Historian.
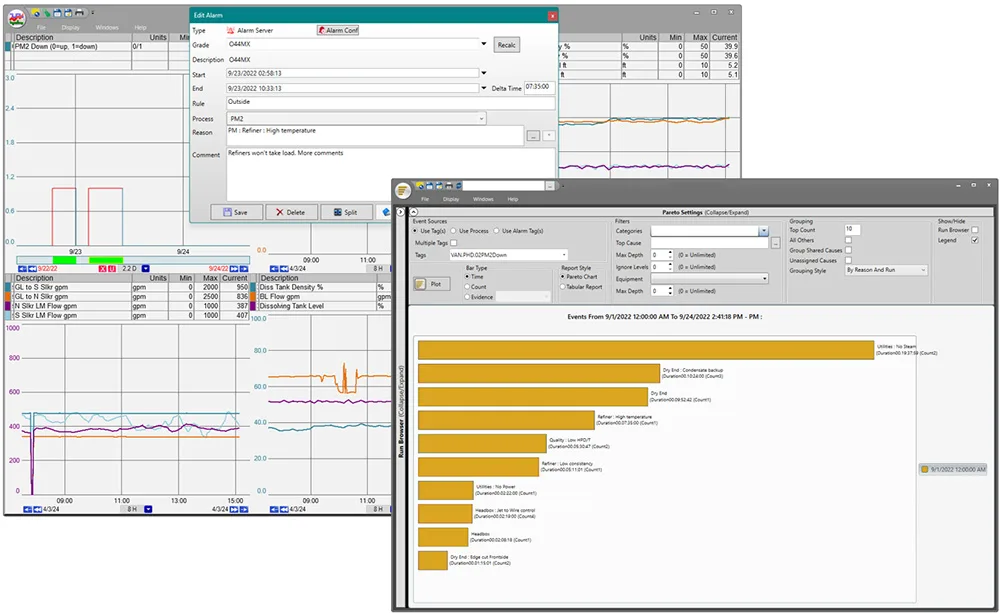
Grâce aux données historiques, les utilisateurs peuvent examiner les événements d’arrêt passés dans un diagramme de Pareto afin d’identifier les causes les plus courantes et de réduire les occurrences futures.
Dépannage qualité
Avec SCADA : les opérateurs peuvent consulter des valeurs en temps réel telles que la température, la pression ou le débit, mais la comparaison des performances entre les cycles de production ou les équipes nécessite des exportations manuelles et une analyse sur tableur. Les tendances SCADA manquent souvent de données de laboratoire synchronisées ou d’identifiants de produits, ce qui rend difficile d’isoler le moment où un écart a commencé ou le lot qui a été affecté.
Avec dataPARC Historian : les données de qualité et de processus peuvent être analysées ensemble en haute résolution. Les utilisateurs peuvent superposer les résultats de laboratoire, les codes produit et les points de consigne du processus afin de déterminer exactement quand les écarts se sont produits et dans quelles conditions. En comparant les bons et les mauvais lots, les ingénieurs peuvent appliquer une analyse multivariée (PCA, PLS) pour identifier les variables de processus, ou leurs combinaisons, qui sont les plus fortement corrélées aux écarts de qualité, ce qui permet un contrôle statistique du processus et des corrections anticipées.
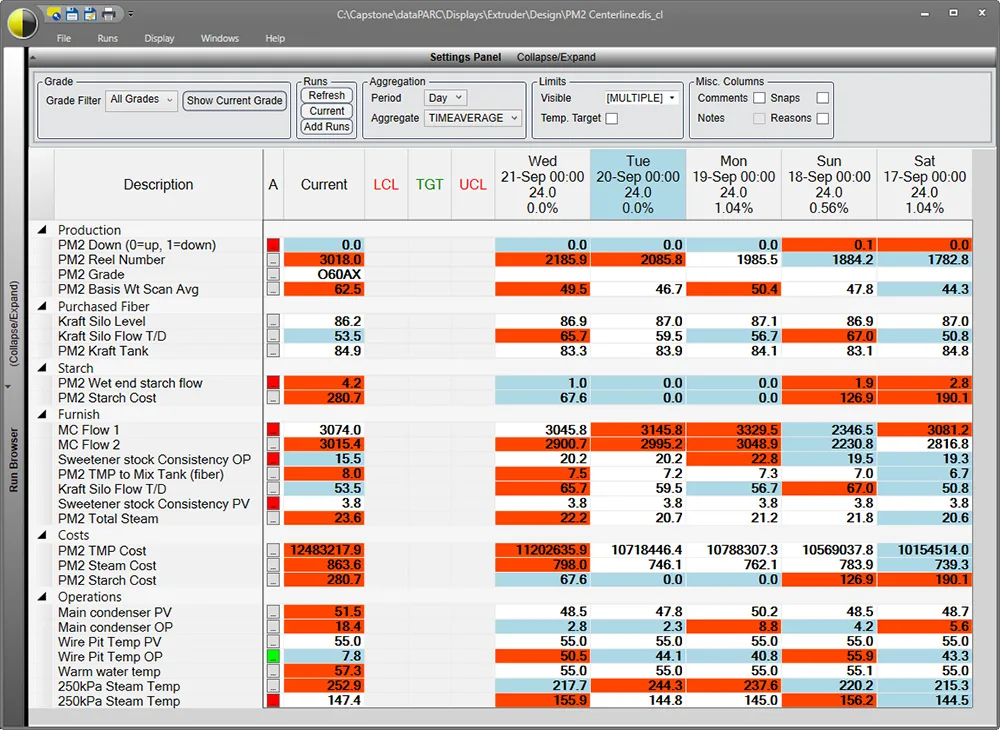
Un affichage PARCview unique appelé « Centerline » peut être utilisé pour le contrôle qualité et pour comparer les données historiques des cycles ou des lots, en mettant en évidence les valeurs supérieures ou inférieures à la moyenne, ce qui permet d’identifier les variables à examiner.
Coût de production et efficacité énergétique
Avec SCADA : la consommation d’énergie ou de matériaux est généralement surveillée en temps réel, mais les calculs de coûts sont effectués ultérieurement dans des systèmes commerciaux distincts. La visibilité sur le coût par unité produite est limitée et les opérateurs ne disposent d’aucun retour d’information immédiat pour optimiser les processus.
Avec dataPARC Historian : la consommation d’énergie et de services publics peut être combinée avec le débit du processus et l’utilisation des matériaux pour calculer le coût par unité en temps réel. L’analyse historique permet d’établir une corrélation entre les conditions d’exploitation, les performances des équipements et l’intensité énergétique. Cela aide les ingénieurs à identifier les zones d’exploitation les plus efficaces, à quantifier les projets d’amélioration et à justifier les changements de processus à l’aide de données de coûts réelles.
L’accès aux données historiques permet d’effectuer des calculs tels que le suivi des écarts afin de comparer les performances actuelles du processus à celles de la production passée.
Communication entre les équipes
Avec SCADA : les transferts entre équipes reposent largement sur les notes des opérateurs ou la communication verbale. La visibilité des données est limitée à ce qui est actuellement affiché sur l’IHM, et l’historique des tendances est souvent réinitialisé chaque jour. Les informations importantes provenant des équipes précédentes sont facilement perdues, ce qui entraîne des dépannages incohérents et des investigations répétées.
Avec dataPARC Historian : tous les utilisateurs ont accès au même historique des tendances, des alarmes et des commentaires des opérateurs grâce à des outils intégrés tels que Logbook. Les ingénieurs peuvent examiner l’activité des équipes précédentes, confirmer les mesures correctives et analyser les problèmes récurrents à l’aide des données réelles du processus. Cette cohérence réduit les temps d’arrêt et améliore la coordination entre les équipes d’exploitation et d’ingénierie.
Bien que Logbook soit une fonctionnalité de PARCview plutôt que de dataPARC Historian, il illustre néanmoins l’importance des données historiques et de l’accès aux informations passées.
Ces exemples illustrent un principe fondamental : les systèmes SCADA sont conçus pour le contrôle, tandis que les historiens sont conçus pour la compréhension. Un historien tel que dataPARC Historian permet aux équipes de dépasser la prise de décision réactionnaire pour s’orienter vers l’amélioration continue, où chaque point de données contribue à l’optimisation et à la fiabilité des processus.
Pourquoi les équipes intelligentes vont au-delà du SCADA pour l’analyse
À mesure que les industries de transformation évoluent vers une prise de décision centrée sur les données, les ingénieurs reconnaissent de plus en plus que le SCADA seul ne peut pas répondre aux exigences analytiques et diagnostiques de la fabrication moderne. Les systèmes SCADA sont indispensables pour le contrôle et la sécurité, mais leur architecture n’a jamais été conçue pour gérer le volume, la vitesse et la variété des données générées par les usines d’aujourd’hui.
De nombreuses usines tentent d’utiliser le SCADA comme un historien de fortune en exportant les données vers des tableurs ou des bases de données externes, mais cette approche pose ses propres problèmes. La synchronisation temporelle entre les sources devient peu fiable, les métadonnées sont perdues et la manipulation manuelle peut facilement introduire des erreurs. Le manque d’informations contextuelles, telles que la qualité des produits, l’état des équipements ou les résultats de laboratoire, rend l’analyse à long terme fastidieuse et incohérente.
Un historien dédié résout ces problèmes en fournissant des données chronologiques contextualisées à haute résolution qui peuvent être utilisées pour des analyses avancées, la validation de modèles et l’amélioration continue. Il fournit la base nécessaire au dépannage avancé, au développement de modèles et aux efforts d’amélioration continue dans toute l’usine. Supposons que votre installation cherche à améliorer sa stratégie en matière de données. Dans ce cas, le déploiement d’un historien est une première étape cruciale, d’autant plus que l’IA et les outils d’analyse tiers s’appuient de plus en plus sur des données historiques riches pour obtenir des résultats.
Aller au-delà du SCADA permet également de soutenir des initiatives d’analyse plus larges, telles que :
- La maintenance prédictive, qui utilise les données à long terme sur les vibrations, la température et le temps de fonctionnement pour prévoir les pannes d’équipement.
- L’optimisation de l’énergie et des ressources, qui met en corrélation l’utilisation des services publics avec le taux de production et les conditions ambiantes.
- L’analyse de la capacité et de la variabilité des processus, qui utilise les techniques SPC pour quantifier la stabilité dans le temps.
- La traçabilité de la production, qui relie les données de processus aux enregistrements de lots, aux résultats de laboratoire et à la qualité du produit final.
En adoptant une architecture basée sur l’historique, les usines peuvent passer d’une réponse aux événements à une optimisation basée sur les données. Au lieu de se fier uniquement à l’intuition des opérateurs, les ingénieurs ont accès à des données validées et synchronisées dans le temps qui permettent une analyse quantitative. Cela accélère les investigations sur les causes profondes, raccourcit les cycles de dépannage et fournit une base empirique pour l’amélioration continue et les initiatives basées sur l’IA.
En bref, le SCADA assure le bon fonctionnement du processus en toute sécurité, mais l’historique garantit qu’il fonctionne de manière efficace et intelligente.
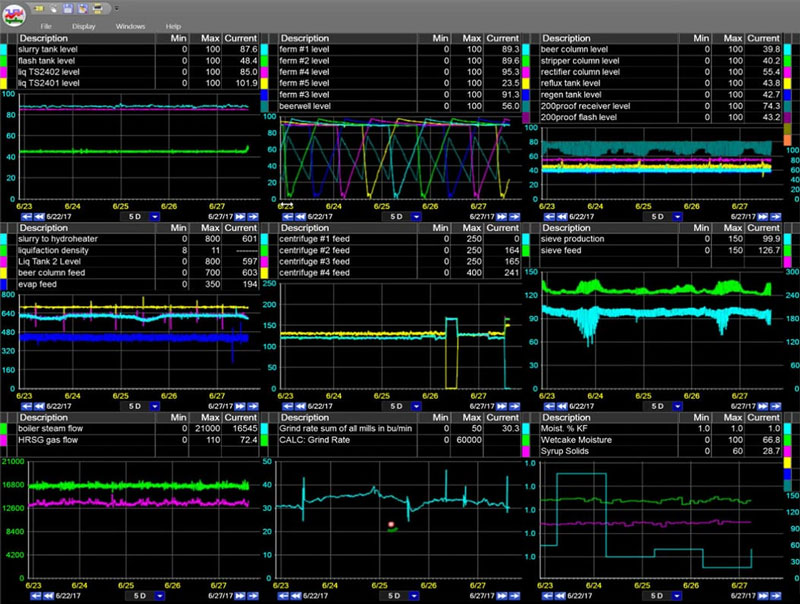
Fonctionnalité d’historique des données d’entreprise à un coût réduit. Outils de collecte et d’analyse de données chronologiques industrielles.
Comment dataPARC comble le fossé
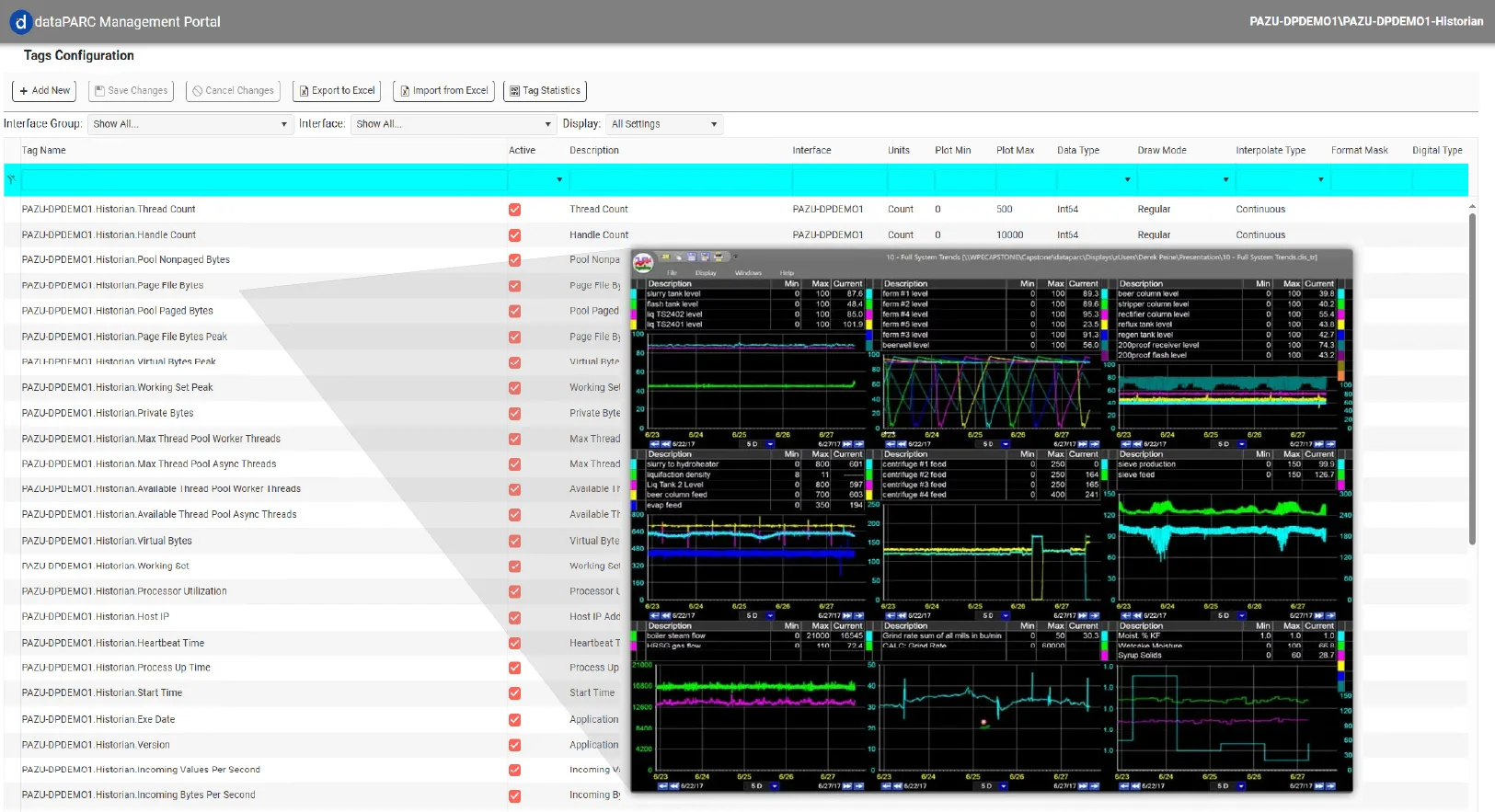
Dans la plupart des environnements de fabrication, les systèmes SCADA constituent l’épine dorsale du contrôle en temps réel, tandis que les historiens servent de base à l’analyse à long terme. Cependant, la véritable valeur ajoutée apparaît lorsque ces deux systèmes fonctionnent ensemble de manière transparente. dataPARC Historian est conçu pour combler ce fossé en combinant une collecte de données à haut débit avec des analyses contextuelles évolutives qui couvrent à la fois les domaines opérationnels et techniques.
dataPARC Historain prend en charge les protocoles industriels standard tels que OPC DA, OPC UA et gRPC, permettant aux ingénieurs d’intégrer les informations provenant des systèmes d’automatisation des processus, des laboratoires et des entreprises sans avoir recours à des interfaces personnalisées complexes. Cette intégration garantit que les variables de processus, les données de laboratoire et les mesures de production sont toutes synchronisées dans le temps et stockées avec des métadonnées cohérentes.
Il en résulte une couche de données centralisée qui prend en charge plusieurs cas d’utilisation :
- Les opérations bénéficient de tableaux de bord en temps réel et de résumés d’alarmes.
- Les ingénieurs de processus ont accès à des données chronologiques détaillées pour l’analyse, la validation des modèles et le dépannage.
- Les équipes qualité établissent une corrélation entre les données sur les produits et les conditions de processus.
- La direction bénéficie d’une meilleure visibilité sur les indicateurs clés de performance, l’efficacité de la production et le coût unitaire.
dataPARC n’est pas seulement un référentiel de données, mais aussi une plateforme d’analyse contextuelle. Les ingénieurs peuvent appliquer des limites spécifiques aux produits, agréger par lot ou par équipe et suivre l’évolution de plusieurs variables sur différentes périodes sans avoir à exporter les données vers des tableurs.
Grâce à la collaboration entre PARCview et l’historique dataPARC, il est possible d’effectuer une surveillance prédictive de la qualité, d’émettre des alertes précoces et d’analyser les écarts sans avoir besoin de couches supplémentaires de transformation des données. La fonction Logbook intégrée offre un moyen structuré de saisir les commentaires des opérateurs et des ingénieurs, alignant ainsi les connaissances humaines sur les données de processus pour obtenir un enregistrement opérationnel plus complet.
Contrairement à de nombreux systèmes d’historique et de visualisation qui nécessitent une assistance informatique spécialisée pour leur configuration, dataPARC est conçu pour être accessible aux ingénieurs. Les utilisateurs peuvent configurer des balises, créer des tableaux de bord et analyser des données grâce à une interface intuitive qui reflète la façon dont les ingénieurs appréhendent les relations entre les processus. Cette accessibilité garantit une adoption plus rapide et une utilisation plus cohérente dans tous les services.
Dans la pratique, dataPARC devient le pont entre le contrôle et la compréhension. Il relie l’immédiateté du SCADA à la profondeur analytique d’un système d’historisation, permettant aux équipes non seulement de voir ce qui se passe, mais aussi de comprendre pourquoi. En combinant la visibilité en temps réel avec le contexte historique, les fabricants peuvent optimiser les performances des processus, améliorer la qualité des produits et permettre des opérations plus intelligentes, basées sur les données.
Historique des données rapide et évolutif à un coût réduit. Découvrez l’historique dataPARC.
 :Choisissez des outils qui évoluent avec vous
L’évolution du contrôle basé sur le SCADA vers la connaissance guidée par l’historique représente un changement dans la manière dont les données de processus sont valorisées et utilisées. Les systèmes SCADA restent essentiels pour le contrôle en temps réel et la sécurité des opérateurs, mais ils n’ont jamais été conçus pour stocker, contextualiser ou analyser des données à l’échelle requise pour l’optimisation moderne des processus.
Pour les ingénieurs de processus, la visibilité à long terme est essentielle. Sans contexte historique, il est impossible de vérifier les améliorations de performances, d’identifier les dérives progressives des processus ou de soutenir des initiatives basées sur les données telles que le contrôle basé sur des modèles et l’analyse prédictive. Un historien fournit cette base en garantissant que chaque balise, alarme et événement est stocké, synchronisé dans le temps et accessible pour analyse.
L’historique dataPARC, associé à PARCview, étend cette capacité en intégrant la visualisation en temps réel, l’analyse contextuelle et la connectivité intersystèmes dans un environnement unique. Les ingénieurs peuvent passer de manière transparente de la surveillance des processus en direct à l’examen historique, de l’analyse des causes profondes à l’évaluation des coûts et de la qualité, le tout sans perte de données ou de contexte.
Il est essentiel de choisir des outils qui s’adaptent à votre activité. Un système qui capture aujourd’hui des données à haute fréquence doit également prendre en charge les objectifs d’analyse et de transformation numérique de demain. Avec dataPARC, les équipes disposent d’une plateforme conçue à la fois pour la fiabilité opérationnelle et l’amélioration à long terme, garantissant que les données de processus ne sont pas seulement un enregistrement de ce qui s’est passé, mais une ressource pour l’apprentissage et l’optimisation continus.
FAQ : Historiens vs SCADA
- Pourquoi les données historiques à long terme sont-elles importantes pour l’optimisation des processus ?
Les données à long terme permettent aux ingénieurs de détecter les dérives lentes des processus, d’identifier les événements récurrents liés aux temps d’arrêt et de vérifier l’impact des changements apportés aux processus. Sans elles, l’amélioration continue devient une question de conjecture. Les données historiques haute résolution prennent en charge le contrôle statistique des processus, l’analyse prédictive de la qualité et la prise de décision basée sur des modèles, qui sont des composants essentiels des stratégies de fabrication avancées. - Comment un historien s’intègre-t-il au SCADA et aux autres systèmes de l’usine ?
Un historien se connecte aux systèmes SCADA, DCS et PLC via des protocoles industriels standard tels que OPCDA, OPCUA, OPCHDA ou d’autres types. Des outils de visualisation tels que PARCview peuvent alors s’interfacer avec l’historien, les systèmes d’information de laboratoire, les bases de données ERP et les systèmes de maintenance. Cette intégration permet aux ingénieurs d’aligner les données de production avec les informations sur la qualité, les coûts et les actifs pour obtenir une vue complète du processus. - Quels types d’analyses sont rendus possibles par dataPARC Historian qui ne sont pas possibles dans SCADA ?
Grâce à un historien complet, les équipes ont accès à différents types d’analyses, soit avec PARCview, soit avec des intégrations tierces. Les sites peuvent effectuer des corrélations multivariables, des analyses d’intensité énergétique et des validations de modèles prédictifs. Ils peuvent également créer des tableaux de bord qui combinent les données de processus, de laboratoire et commerciales dans une seule vue. Ces capacités transforment les données d’un outil de surveillance en une base pour l’amélioration continue, l’analyse de la fiabilité et la prise de décision stratégique. - Quels sont les avantages d’un historien en termes de performances par rapport au stockage de données SCADA ?
Les historiens utilisent des algorithmes spécialisés de compression, d’indexation et de récupération pour stocker efficacement de grands volumes de données chronologiques. Les temps de requête restent proches du temps réel, même pour des ensembles de données couvrant plusieurs années. Cela permet aux ingénieurs d’étudier les tendances des données sur de longues périodes sans dégradation des performances ni perte de détails. - Comment l’historien dataPARC améliore-t-il la collaboration entre les opérateurs et les ingénieurs?
L’historique dataPARC offre un accès partagé à des données haute résolution, des tableaux de bord et des outils contextuels tels que Logbook. Les opérateurs, les ingénieurs et les équipes qualité peuvent tous consulter le même historique, examiner les tendances annotées et corréler les données de processus avec des commentaires ou des événements. Cette visibilité unifiée réduit les lacunes en matière de communication et garantit la cohérence entre les équipes et les services. Il s’agit de vos données et toutes les personnes de votre site qui ont besoin d’y accéder doivent pouvoir le faire.





