Les fabricants accélèrent leurs investissements dans l’IA, mais la plupart se heurtent rapidement au même défi : l’IA ne peut apporter de valeur ajoutée que si l’infrastructure de données sous-jacente est prête à l’accueillir. C’est là qu’intervient un facilitateur d’IA. Au lieu de remplacer les systèmes existants ou d’imposer une refonte numérique complète, un facilitateur d’IA fournit le tissu conjonctif qui rassemble les données de l’usine, les résultats de laboratoire et les systèmes d’entreprise d’une manière qui permet aux outils d’analyse et d’apprentissage automatique de les utiliser efficacement.
Ce blog explore comment dataPARC fonctionne comme un puissant facilitateur d’IA pour les fabricants, aidant les équipes à unifier leurs données, à créer et déployer des modèles plus rapidement, et à fournir des informations d’IA en temps réel aux opérateurs qui prennent les décisions.
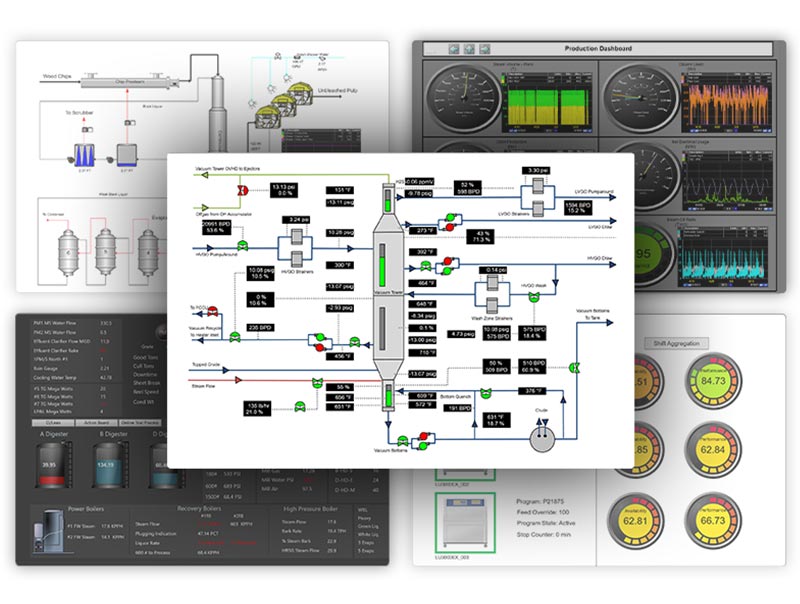
Préparez votre écosystème de fabrication avec un historien de données rapide et une surveillance des processus.
Pourquoi les fabricants ont besoin d’une couche d’activation de l’IA
L’IA et l’apprentissage automatique s’immiscent dans tous les aspects de la fabrication, de la prévision de la qualité à l’optimisation énergétique. Mais ces modèles ne peuvent apporter de valeur ajoutée que si les usines peuvent leur fournir les données appropriées, puis transmettre les résultats aux opérateurs suffisamment rapidement pour leur permettre de prendre des décisions éclairées. Les systèmes d’IA ont besoin de données accessibles, connectées entre les différents services et riches en contexte, telles que les cycles de production, les valeurs de laboratoire, les notes des opérateurs et les événements.
La plupart des usines ne fonctionnent pas ainsi par défaut. Les données de processus se trouvent dans un système, les données de laboratoire dans un autre, les données de maintenance dans un troisième et les systèmes d’entreprise dans leurs propres environnements isolés. Même lorsque toutes ces sources existent, elles parlent rarement le même langage ou partagent la même structure. Cet écart rend difficile la création ou le déploiement de modèles, sans parler de la confiance dans leurs résultats dans les opérations réelles.
C’est pourquoi les fabricants ont besoin d’une couche d’activation de l’IA. Elle sert de pont entre l’OT et l’IT, en intégrant les signaux de processus, les résultats de laboratoire, les cycles et les événements dans un environnement unifié et prêt pour l’analyse. Au lieu d’obliger les équipes à créer des intégrations personnalisées ou à réorganiser l’infrastructure existante, une couche d’activation fournit la connectivité et le contexte nécessaires aux modèles, tout en renvoyant les résultats de l’IA aux opérateurs et aux ingénieurs en temps réel.
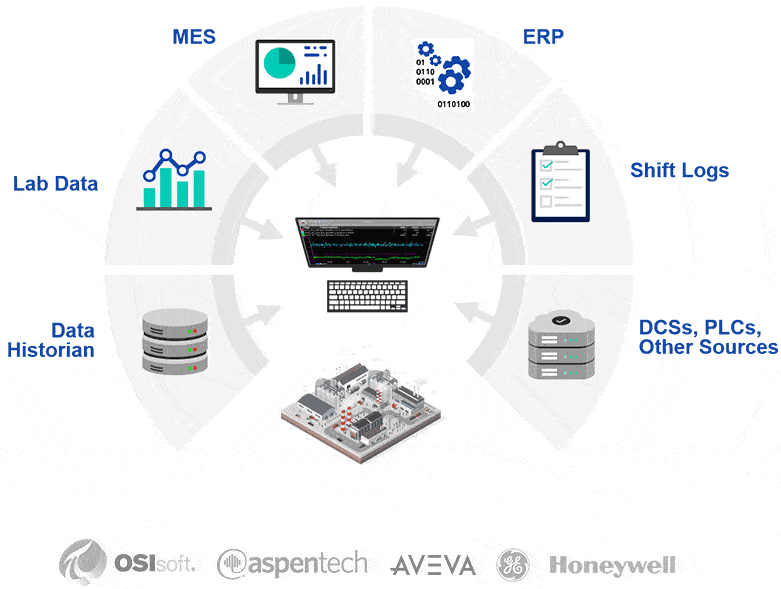
PARCview rassemble les données de tous vos systèmes en un seul endroit et peut ensuite les envoyer à un système d’IA tiers pour une analyse plus approfondie, toutes les données étant alignées et regroupées.
En bref, l’IA échoue lorsqu’elle ne dispose que de données brutes. Elle réussit lorsque ces données sont organisées, contextualisées et accessibles dans toute l’usine. Une couche d’activation de l’IA rend cela possible, offrant aux fabricants une base pratique et évolutive pour appliquer des analyses avancées sans perturber les opérations quotidiennes.
Comment dataPARC relie les opérations à l’IA et à l’apprentissage automatique
Pour que l’IA soit utile au sein d’une usine, les données doivent circuler de manière fluide entre les systèmes opérationnels et les outils analytiques qui entraînent, valident et exécutent les modèles. dataPARC fournit ce point de connexion en créant un environnement de données unifié qui relie les opérations en temps réel aux plateformes modernes d’IA et d’apprentissage automatique.
À la base se trouve une connectivité unifiée. dataPARC intègre les données de processus, de laboratoire, de maintenance et d’entreprise via des interfaces OPC, SQL, REST et cloud, éliminant ainsi les silos qui séparent généralement les systèmes OT et IT. Cela permet aux ingénieurs et aux scientifiques des données de travailler à partir du même ensemble de données cohérent sans avoir à créer de connecteurs personnalisés ou de workflows manuels.
dataPARC applique ensuite la contextualisation, en alignant les données brutes des balises avec les cycles de production, les résultats de laboratoire, les commentaires des opérateurs et l’historique des événements. Cela crée un modèle structuré et prêt à être analysé, essentiel pour une ingénierie précise des fonctionnalités, la sélection des données pour la formation et les performances à long terme du modèle. Les outils d’IA reçoivent des entrées propres et cohérentes plutôt que des flux de données fragmentés ou ambigus.
Une fois les modèles construits, dataPARC boucle la boucle grâce à des flux de travail. Les prédictions du modèle, les scores de confiance ou les points de consigne recommandés peuvent être directement transmis aux tableaux de bord PARCview, où les opérateurs et les ingénieurs surveillent déjà leurs processus. Cela permet une aide à la décision en temps réel et garantit que les informations issues de l’IA ne sont pas piégées dans d’autres systèmes ou rapports hors ligne.
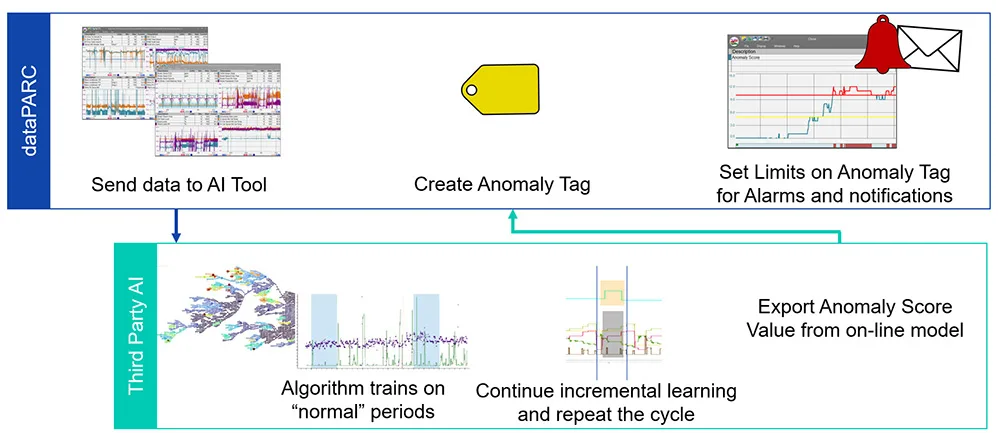
Cela montre les étapes suivies par dataPARC et une IA tierce, les données brutes étant envoyées au logiciel d’IA et réinsérées dans dataPARC sous forme de balise afin de déclencher une alarme en cas de valeurs élevées.
En coulisses, l’intégration transparente de dataPARC garantit un flux de données fiable dans les deux sens, de l’usine vers le cloud pour le développement de modèles et des modèles vers les opérations pour une utilisation quotidienne.
Il en résulte un environnement pratique et prêt pour la production, dans lequel l’IA fait partie intégrante des flux de travail quotidiens de l’usine, et non un exercice analytique distinct.
Transmettre les informations issues de l’IA aux opérateurs en temps réel
Pour vous assurer que votre système est prêt pour l’IA, vérifiez que les données sous-jacentes sont complètes, contextualisées et alignées entre les systèmes. dataPARC transforme les données brutes de l’usine en informations prêtes pour l’IA en les préparant pour la modélisation, l’analyse et l’inférence en temps réel.
La plateforme agrège les informations provenant des systèmes OT et IT, des balises de processus, des valeurs de laboratoire, des cycles de production, des événements d’arrêt et des commentaires des opérateurs, et les structure dans un modèle unifié. Cela élimine les formats incohérents, les différences de nomenclature et les décalages temporels qui ralentissent généralement le développement des modèles. Les données organisées par domaine de processus aident à contextualiser ces informations.
Lorsque les modèles sont prêts à être déployés, dataPARC permet une inférence en temps réel en renvoyant les signaux nécessaires dans l’environnement de l’usine. Les résultats des modèles qui peuvent être exportés vers un dossier ou un fichier peuvent être automatiquement importés dans une balise PARCview. L’utilisateur peut ainsi suivre l’évolution de la valeur, définir une alarme ou la visualiser dans un tableau de bord. Cela garantit que les informations issues de l’IA parviennent aux opérateurs, aux ingénieurs et aux superviseurs au moment où les décisions sont prises.
En transformant des données déconnectées en intelligence opérationnelle structurée, dataPARC élimine l’un des principaux obstacles à l’adoption de l’IA industrielle : rendre les informations utilisables, cohérentes et exploitables à grande échelle.
Cas d’utilisation pratiques de l’IA que vous pouvez déployer dès aujourd’hui
Comme dataPARC offre une connectivité unifiée, une contextualisation et une visualisation en temps réel, les fabricants peuvent déployer des applications d’IA pertinentes sans avoir à remplacer les systèmes existants. Voici quelques exemples d’utilisation quotidienne que vous pouvez essayer :
Maintenance prédictive
- Détectez rapidement la dégradation des équipements à l’aide de modèles de détection des anomalies ou de prédiction des pannes.
- Insérez les scores de prédiction de surface directement dans PARCview pour guider la planification de la maintenance.
Prédiction et optimisation de la qualité
- Connectez les modèles de qualité ML aux conditions de production en temps réel.
- Fournissez aux opérateurs des prédictions en temps réel sur les risques de non-conformité et les ajustements recommandés.
Optimisation de l’énergie et des services publics
- Utilisez l’IA pour mettre en évidence les inefficacités dans l’utilisation de la vapeur, de l’électricité, de l’eau ou de l’air comprimé.
- Transmettez les recommandations d’optimisation aux opérateurs pour qu’ils puissent prendre des mesures immédiates.
Optimisation des processus
- Soutenez l’amélioration continue grâce à des modèles qui recommandent des ajustements des points de consigne ou détectent les dérives de processus.
- Comparez les performances attendues et réelles côte à côte dans PARCview.
Prévision et planification de la demande
- Intégrez les modèles de prévision aux tableaux de bord de production.
- Alignez les opérations sur la demande prévue, les prix ou les contraintes d’approvisionnement.
Ces applications ont toutes une exigence commune : des données accessibles, cohérentes et contextualisées. En fournissant cette base et en intégrant les informations dans les flux de travail quotidiens, dataPARC aide les fabricants à passer de projets d’IA exploratoires à des résultats opérationnels concrets.

Vous vous demandez à quoi ressemble un écosystème de données prêt pour l’IA ? Cette vidéo vous explique tout.
Pourquoi les fabricants choisissent dataPARC pour l’activation de l’IA
dataPARC se distingue parce qu’il rend l’IA pratique, utilisable et évolutive dans des environnements industriels réels. Au lieu d’imposer aux équipes des architectures rigides ou des flux de travail exclusivement axés sur la science des données, il permet aux opérateurs, aux ingénieurs et aux analystes de travailler à partir de la même base de données fiable. Les fabricants choisissent dataPARC parce qu’il offre :
Une facilité d’utilisation conçue pour les opérations
Conçu pour les ingénieurs et les opérateurs, dataPARC fournit des outils intuitifs pour la visualisation, le dépannage et l’aide à la décision. Les informations issues de l’IA s’intègrent dans le flux de travail existant, et ne constituent pas un projet d’analyse isolé.
Une infrastructure évolutive et fiable
Qu’il s’agisse d’une seule usine ou d’une entreprise multi-sites, dataPARC gère de manière fiable les données haute résolution, le stockage à long terme et les architectures hybrides. Il prend en charge les environnements sur site, dans le cloud et mixtes sans compromettre les performances ou le contrôle.
Connectivité OT-IT unifiée
dataPARC intègre les plateformes SCADA, DCS, les systèmes de laboratoire, MES, ERP et d’analyse cloud dans un environnement unique. Cette vue unifiée permet aux modèles d’IA d’accéder à l’ensemble du contexte opérationnel dont ils ont besoin.
Intégration transparente avec les outils d’IA/ML
Que les équipes utilisent Azure, Databricks, Python, Snowflake ou des pipelines de science des données internes, dataPARC fournit des données propres et contextualisées pour la formation et l’inférence. Les résultats des modèles sont renvoyés vers PARCview pour une mise en œuvre en temps réel.
Fiabilité éprouvée dans tous les secteurs
dataPARC a gagné la confiance des secteurs de la pâte à papier et du papier, des produits chimiques, du raffinage, de la production d’électricité, de l’alimentation et des boissons, et bien d’autres encore. Les usines s’appuient sur lui pour garantir la disponibilité, l’intégrité des données et la possibilité de faire évoluer leurs efforts en matière d’IA sans avoir à reconstruire les systèmes existants.
Une voie pratique vers l’adoption de l’IA
Au lieu d’exiger une refonte numérique complète, dataPARC s’adapte aux équipes telles qu’elles sont. Il fait le lien entre les opérations actuelles et les analyses avancées, rendant l’adoption de l’IA progressive, réalisable et alignée sur les besoins de production quotidiens.
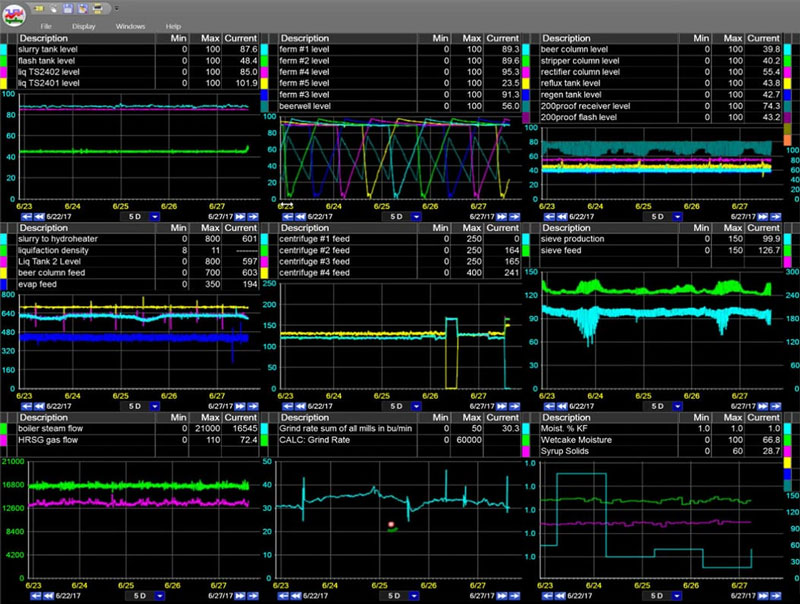
Découvrez les outils d’analyse des données de processus en temps réel de dataPARC et voyez comment de meilleures données peuvent conduire à de meilleures décisions.
FAQ: dataPARC en tant que facilitateur de l’IA pour la fabrication
- Que signifie le fait qu’une plateforme soit un « facilitateur d’IA » dans le secteur manufacturier ?
Un facilitateur d’IA fournit l’infrastructure de données sous-jacente nécessaire au bon fonctionnement de l’IA et de l’apprentissage automatique. Cela comprend la connexion des données OT et IT, la contextualisation des signaux, le stockage d’un historique haute résolution et la fourniture d’ensembles de données propres et accessibles aux outils d’analyse. dataPARC y parvient en unifiant les données de processus, de laboratoire et d’entreprise et en les rendant prêtes pour l’IA sans perturber les opérations en cours. - Dois-je remplacer mes systèmes existants pour utiliser l’IA avec dataPARC ?
Pas nécessairement. dataPARC dispose d’un historien ; la couche d’intégration et de visualisation, PARCview, s’ajoute à vos historiens existants, vos réseaux DCS/PLC, vos systèmes de laboratoire et vos bases de données d’entreprise. Elle agit comme une couche unificatrice plutôt que comme un remplacement. Cela permet aux fabricants d’adopter l’IA de manière progressive, en s’appuyant sur l’infrastructure actuelle tout en modernisant leur environnement de données à leur propre rythme. - Quels types de cas d’utilisation de l’IA dataPARC peut-il prendre en charge aujourd’hui ?
dataPARC est utilisé dans un large éventail d’applications basées sur l’IA, notamment la maintenance prédictive, la prévision de la qualité, l’optimisation des processus, la surveillance des émissions, l’équilibrage énergétique, la prévision de la demande, etc. Ses données contextualisées permettent à ces cas d’utilisation de s’intégrer directement dans les opérations quotidiennes. - Les opérateurs et les ingénieurs peuvent-ils réellement utiliser les informations issues de l’IA dans PARCview ?
Oui. Les prévisions des modèles, les paramètres recommandés, les scores d’anomalie ou les estimations de qualité peuvent être affichés directement dans les tableaux de bord PARCview. Cela permet aux opérateurs de voir les conseils de l’IA dans le contexte des tendances en temps réel et des données sur les équipements, ce qui leur permet de prendre des décisions plus rapides et plus sûres. - Comment dataPARC s’adapte-t-il à l’adoption croissante de l’IA ?
La plateforme est conçue pour une évolutivité à long terme, prenant en charge tout, des déploiements dans une seule installation aux systèmes à l’échelle de l’entreprise. Elle gère l’augmentation du nombre de balises, la croissance des volumes de données et les charges de travail de modélisation supplémentaires sans compromettre les performances. À mesure que de nouvelles applications d’IA sont introduites, dataPARC devient la colonne vertébrale centralisée des données qui permet de tout harmoniser et de tout rendre accessible.
Digital Transformation Roadmap
Download our Digital Transformation Roadmap and learn what steps you can take to achieve data-driven success in manufacturing.







